
테스트웍스의 AI 데이터 품질 전문가 이창신 연구소장은 AI SUMMIT SEOUL 2023에서 ‘AI 데이터의 복잡한 지형에서 길 찾기’라는 강연을 통해 AI 산업 동향과 함께 실제 사례를 중심으로 한 AI 데이터 품질 확보 전략을 공유했습니다.
AI 산업 동향

최근 챗GPT가 세상을 떠들석하게 한 후 생성 AI에 대한 이목이 집중되고 있습니다. 특히, 생성 AI를 통해 텍스트 뿐만 아니라 이미지, 영상, 오디오 등 다양한 데이터를 생성해 멀티모달 AI를 향해 나아가는 시도들이 늘고 있으며, 멀티모달 AI를 위해 로봇 및 자율주행 모빌리티 산업에서는 카메라, 라이다 등 다양한 센서의 활용 기술에 대한 연구가 확대되고 있습니다.
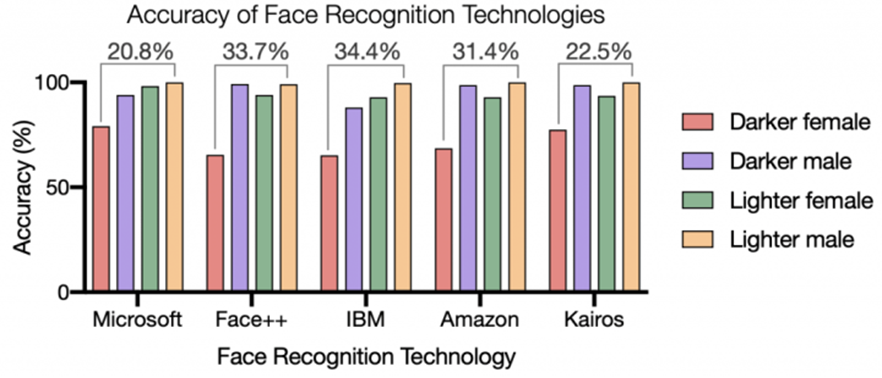
출처 : Racial Discrimination in Face Recognition Technology(2022), SITN
한편, AI 기술이 급격히 발전하는 과정에서 AI가 편향된 데이터를 학습해 차별적인 발언을 하거나, AI가 저작권 이슈가 있는 데이터를 학습해 생성한 이미지 영상에 대한 저작권 문제가 발생하거나, 자율주행의 경우 AI가 사물을 제대로 인식하지 못해 사고를 내는 등 다양한 사회적, 법적, 윤리적 이슈들이 발생하고 있어 신뢰할 수 있는 AI를 개발하기 위한 논의가 활발하게 이뤄지고 있습니다.
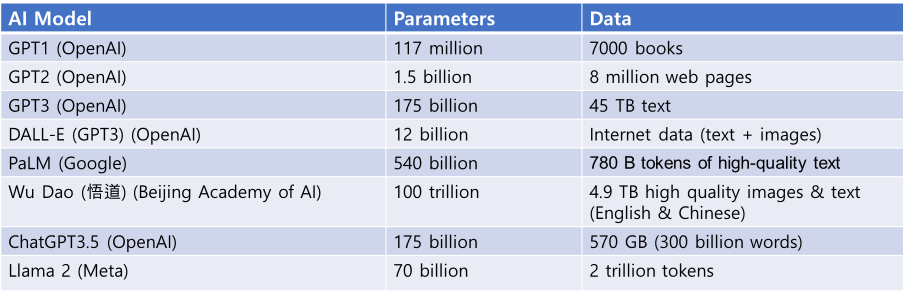
신뢰할 수 있는 AI를 개발하기 위해서는 데이터 중심의 AI 개발이 필수적입니다. 챗GPT와 같은 LLM의 경우, 대부분 기본적으로 파운데이션 모델이라 불리는 트랜스포머 모델을 활용하고 있으며, 모델보다는 파라미터와 데이터의 종류와 양으로 그 모델의 성능이 결정되고 있습니다.
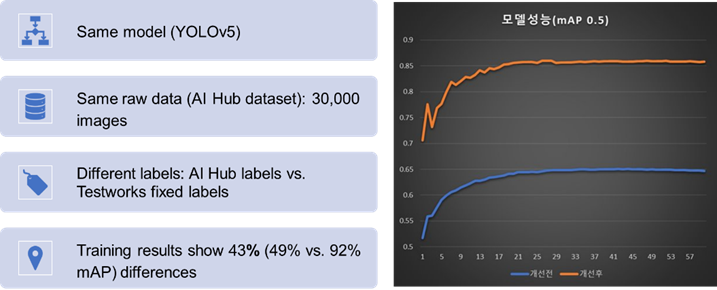
위의 사례와 같이 실제로 같은 모델이더라도 학습하는 데이터의 품질이 높아질 경우, 성능이 크게 개선된 것을 확인할 수 있습니다.
AI 데이터 품질 확보 전략
테스트웍스는 데이터 중심의 AI 개발을 위해 다양한 사례들을 중심으로 데이터 품질을 확보 및 관리하고 있습니다.

데이터 품질을 확보하기 위해서는 데이터를 수집하는 단계에서부터 품질 관리가 수행되어야 합니다. 영화에서 영상과 음성의 동기화가 필수적인 것처럼, 다양한 센서를 통해 데이터를 수집함에 있어 각 센서를 동기화 및 정합하는 작업은 필수적입니다.

테스트웍스는 카메라와 라이다 센서를 동기화하고 정합하는 기술력을 통해 고품질의 3D 데이터를 수집하고 있습니다.
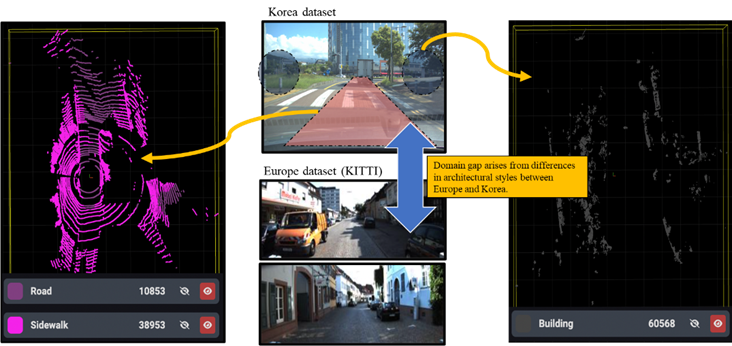
또한, 데이터의 다양성을 확보하기 위해서는 구체적인 목표를 세우고 이를 정량화 해야 합니다. 위의 예시와 같이 유럽의 도로 데이터를 학습한 모델을 활용해 한국의 도로 데이터를 자동 라벨링 진행했을 시 다양성이 확보되지 않아 성능이 떨어지는 것을 확인할 수 있습니다. 그러므로 다양한 데이터를 확보하기 위한 목표를 세우고 정량화하여 다양성이 확보되었는지 평가할 수 있어야 합니다.
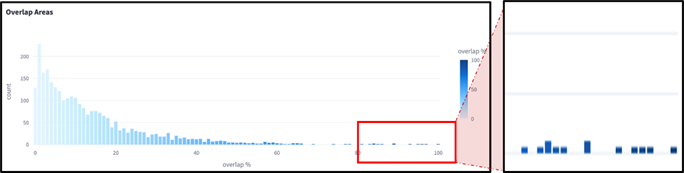
정량화 다음으로는 시각화가 필요합니다. 테스트웍스는 위의 예시와 같이 가공된 데이터를 시각화된 통계를 확인하며, 중첩된 라벨 등 검수로도 확인이 어려운 부분을 찾아내어 품질을 높이고 있습니다.
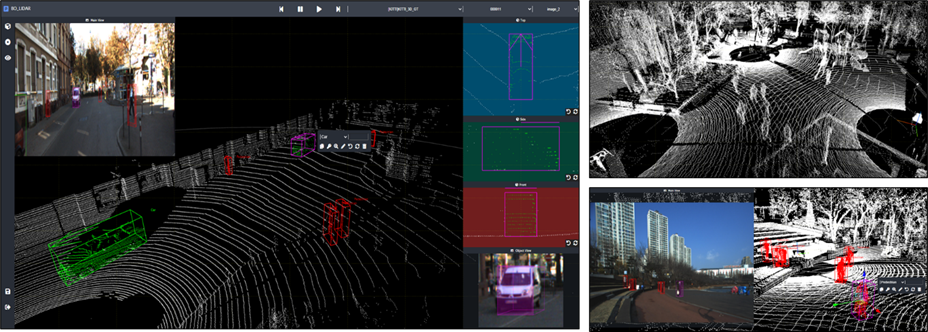
또한, 3D 포인트 클라우드 데이터 가공 시 2D 카메라 이미지를 동시에 보면서 가공하는 기능을 갖춘 데이터 가공 자동화 관리 솔루션 blackolive 2D & 3D를 활용해 데이터 품질을 확보할 수 있습니다.
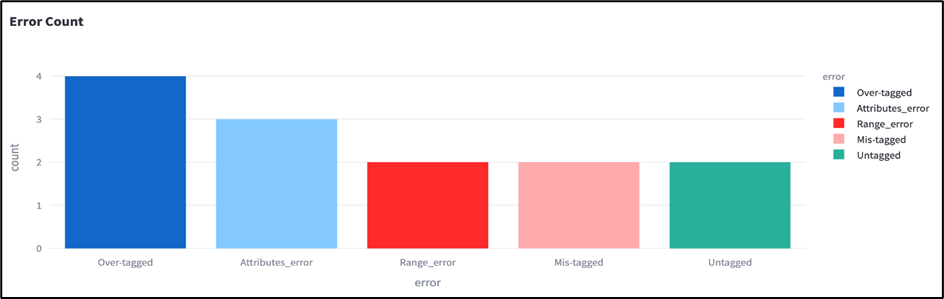
테스트웍스는 대규모 자체 데이터 구축과 자동화 모델 고도화로 자동 라벨링 후 수동 검수 방식으로 생산성을 확보함과 동시에 데이터 검수 시간을 확보해 데이터 품질을 향상시키고 있습니다. 데이터 구축, 데이터 검증 및 개선, 모델 성능 개선 등 AI 도입 및 상용화를 가장 빠르게 지원하는 역량을 보유한 테스트웍스는 고객의 문제 해결 및 서비스 만족을 위해 최선을 솔루션을 제공합니다.