
Changsin Lee l Tech Evangelist l Testworks
교통랑 측정이 Microsoft사와 현대 개인용 컴퓨팅의 급 부상과 관련이 있다는 것을 알고 계셨나요? 교통량 측정은 시 공무원들이 교통 요구 사항을 결정하는 데 사용합니다. 가장 널리 사용되는 방법은 측정하고자 하는 도로에 공압 고무 튜브 스트립을 설치한 뒤 차량 체적, 차량 유형, 차축 수 등과 같은 지표를 분석하는 것입니다. 그러나 이 방법은 부정확하고 안전하지 않아서 더 개선된 방법을 연구하고 있습니다.
이번 블로그 글에서는 공개 데이터 셋을 사용하여 딥 러닝 접근 방식(YOLO V5)을 통한 고유한 교통량 측정 구축 방법을 보여드리려고 합니다. 전체 소스 코드는 Colab 노트북에서 사용할 수 있습니다. 사용된 학습용 데이터 샘플은 Testworks가 가공에 참여하여 AI Hub에 공개 된 데이터 셋으로 30743번 입니다.
문제
흥미롭게도 Bill Gates와 Paul Allen은 Microsoft를 설립하기 전 공압 도로 튜브 데이터를 펀칭하는 수동 프로세스를 일부 자동화하는 작업을 시도했습니다. 그 때 비즈니스 파트너십이 Traf-O-Data로 나중에 Microsoft가 되었습니다. 프로젝트 자체는 그다지 성공적이지 않았지만 그들이 얻은 경험이 결국 Microsoft의 설립과 변천사에 기여했습니다.
공압식 고무 튜브 카운터는 쉽고 널리 사용되는 솔루션이지만 몇 가지 문제가 있습니다.
- 설치 위험: 튜브를 설치하려면 교통량이 많은 도로 한가운데에서 사람의 작업이 선행되어야 하므로, 위험하기도 하며 사고 책임 문제를 야기할 수도 있습니다.
- 마모: 고무 튜브는 자연적으로 마모되기 때문에 정기적으로 교체해야 합니다. 더 심각한 문제는 장치가 부정확한 데이터를 보고하기 시작해도 사람들이 인식하지 못 할 수 있다는 것입니다.
- 부정확성: 더 큰 문제는 공압 튜브에서 수집할 수 있는 데이터가 기껏해야 대략적인 추정치라는 것입니다. 차량 속도와 교통 상황에 따라 잘 못 계산 될 수 있습니다.
- 확장성 문제: 튜브가 간단한 계산 방법을 제공하지만 보행자, 자전거 타는 사람, 운전자, 차량 모델 등과 같은 다른 정보를 수집하려는 경우 공압 고무 튜브를 확장할 수 있는 방법은 없습니다.
이러한 이유로 컴퓨터 비전, 특히 딥 러닝 분야에서는 보다 안전하고 확장 가능한 방법을 모색하고 있습니다. 우수한 성능 향상을 위한 딥 러닝 모델의 핵심은 물론 양질의 학습용 데이터입니다. 좋은 소식은 공개적으로 사용 가능한 무료 데이터 셋이 많이 있다는 것입니다.
다음에서는 공개 데이터에 대한 전이 학습을 통해 교통량 계산 모델의 성능을 향상시키는 방법을 보여 드리겠습니다. 실험을 위해 AI Hub Korea의 샘플 감시 카메라 데이터 셋을 활용할 수 있습니다. 공개 데이터 셋은 고정 지점 감시 카메라에서 찍은 100개의 이미지로 바운딩 박스의 태그가 지정되어 있습니다.
기본 모델: YOLO V5
YOLO(You Only Look Once)는 객체 감지에 성공적으로 사용되는 오픈 소스 딥 러닝 시스템입니다. 여러 분이 소유한 데이터 셋으로 학습시킬 수 있는 사전 학습 모델들도 있습니다. 이를 ‘전이 학습’이라고 하며 자신의 차량 감지 시스템을 신장시키기 위한 좋은 방법입니다. 이를 위해 사전 훈련된 모델과 함께 YOLO V5를 가져와 보겠습니다.

이제 테스트 이미지 데이터를 얻어서 모델을 실행합니다. 모든 이미지를 사용할 수도 있지만 교통 데이터에 관심이 있으므로, 여기에 고속도로 감시 카메라의 일부 이미지를 가져옵니다. 그리고 detect 명령을 실행하여 yolov5 예측을 얻습니다.

각 명령 행 매개변수가 의미하는 바에 대한 자세한 설명은 yolov5 리포지토리(소스코드 저장소) 에서 찾을 수 있습니다. 목적에 맞게 weights 파일(weights 매개변수), 이미지 사이즈(img 매개변수), 신뢰 한계값(conf 매개변수: 0.5는 신뢰값이 최소 50%이어야 함을 의미), 테스트 이미지가 있는 위치인 소스 폴더(source 매개변수)를 지정하면 됩니다. 다음은 감지된 샘플 출력 입니다.
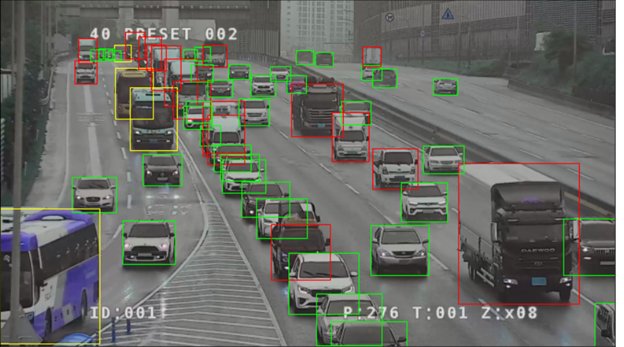
사전 훈련된 모델은 차량을 감지하고 인식하는 데 꽤 좋은 결과를 보여 주지만 뒤에 있는 많은 차량은 놓쳤습니다. 설상가상으로 아래 예시와 같이 한 줄로 늘어선 차들을 기차로 인식하는 경우도 있었습니다.

차량 계산 모델 훈련
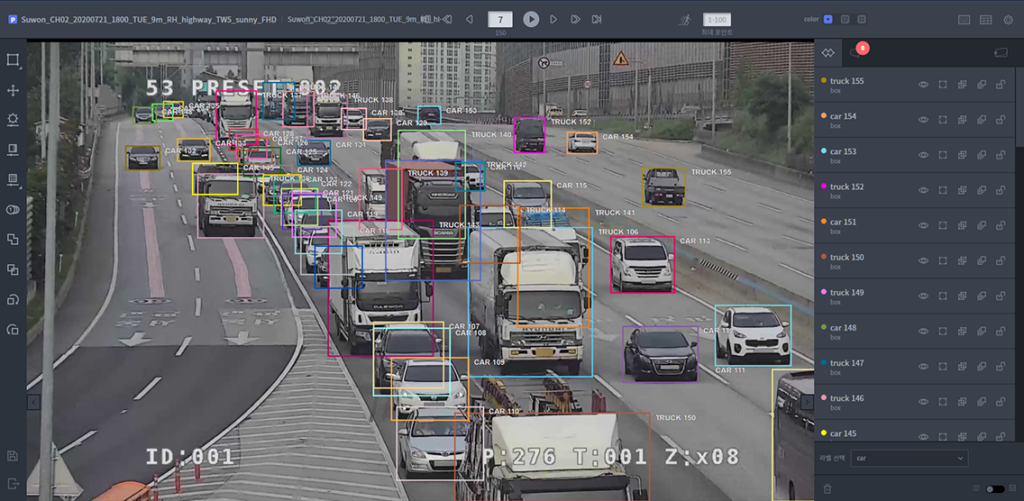
한국 공개 데이터 셋 저장소인 AI Hub에 접속하면, 감시 카메라의 고속도로 이미지를 레이블 한 데이터 셋을 찾을 수 있습니다. 전체 데이터 셋에는 500,000개의 이미지가 포함되어 있습니다. 설명을 위해 100개의 이미지 레이블이 되어 있는 샘플 데이터 셋을 사용하겠습니다. 동일한 샘플 테스트 이미지는 YOLO V5가 놓친 대상의 레이블을 보여줍니다.
YOLO 모델 훈련을 위해서는 몇 가지를 구성해야 합니다. 가장 중요한 것은 레이블 형식과 학습을 위한 설정(config) 파일 입니다. 먼저 설정 파일을 살펴보겠습니다. 이 파일에 사용하려는 데이터 셋(훈련, 검증 및 테스트 데이터 폴더), 클래스 수 및 클래스 이름이 포함되어야 합니다. 이 번 글의 목적이 교통량 측정이므로 세 가지 차량 등급만 있습니다. 다음은 기차 구성 YAML 파일 전체입니다.
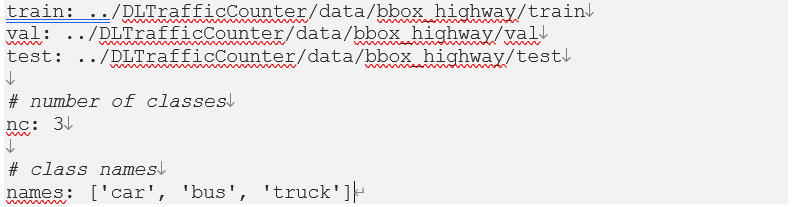
둘째, 각 이미지 파일에 대해 동일한 파일 이름을 가진 해당 *.txt 파일이 있어야 합니다. 각 레이블 텍스트 파일에서 레이블은 다음 형식이어야 합니다.

- 첫 번째 숫자는 클래스 id입니다. id는 훈련 설정 파일의 클래스 이름 목록에 있는 인덱스입니다. 이 경우 2는 목록의 인덱스 2인 ‘트럭’을 의미합니다.
- 다음 두 숫자는 이미지 중심의 x 및 y 좌표(x 와 y 중심점)를 나타냅니다.
- 마지막 두 숫자는 레이블의 너비와 높이입니다.
- 클래스 id를 제외한 모든 숫자는 0과 1 사이에서 정규화 됩니다. 예를 들어, 우리의 경우와 같이 이미지 크기가 (1920, 1080)인 경우 실제 좌표는(0.62772 x 1920 = 1205.22, 0.58336 x 1080 = 630.03, 0.02264 x 1920 = 43.47, 0.0359 x 1080 = 38.77)로 계산 되어야 합니다.
이 정보를 기반으로 주석 파일이 생성되어 학습용 이미지 파일과 동일한 폴더에 저장됩니다. 이제 훈련 스크립트를 실행하여 모델을 학습시킵니다. 배치 당 10개의 이미지가 있는 400개의 주기(epoch)를 사용하고 있습니다.

샘플 훈련 실행 결과는 다음과 같습니다.
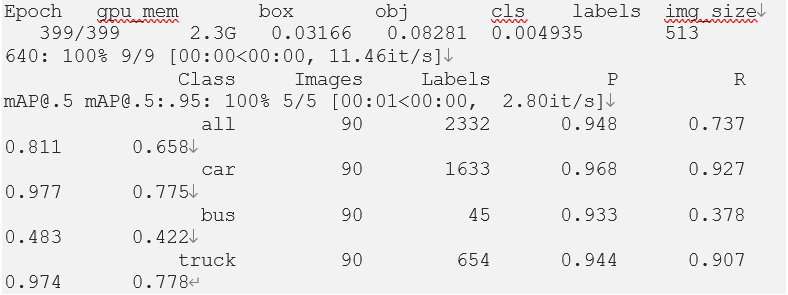
베스트 모델(best.pt)과 마지막 모델(last.pt)은 ‘nosave’ 옵션을 지정하지 않는 한 ‘runs/train/exp/weights’ 폴더에 저장됩니다.
탐지 및 계산
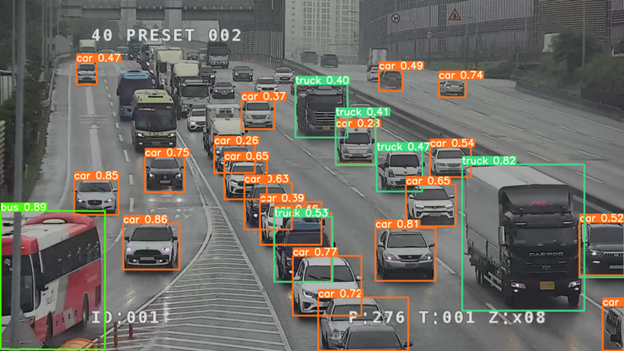
이제 동일한 테스트 이미지에 대해 실행하면 완전히 다른 결과를 얻습니다. 모든 차량을 감지한 것 같습니다.

기차로 감지 되었던 긴 차량 행렬은 어떻게 바뀌었을까요? 기차로 감지하지 않고 각각 다른 차량 유형으로 대체되었습니다.

새로 훈련된 모델이 모든 차량을 올바르게 감지했는지 확인하기 위해 테스트 이미지에서 각 유형의 차량을 실제로 세어 집계해 보겠습니다. 그렇게 하려면 모델에서 반환된 탐지 결과를 파싱(parsing) 해야 합니다.
YOLO가 반환한 탐지 결과에는 우리의 목적에 유용한 다음과 같은 정보가 포함되어 있습니다.
1. results.names에는 클래스 이름이 포함됩니다(예: ‘사람’). 기본적으로 자동차, 버스 및 트럭을 포함한 80개의 COCO 데이터 셋 클래스에 해당하는 객체가 있습니다.
2. results.xyxyn: xy 좌표 다음에 신뢰도 및 클래스 id가 옵니다. 예를 들어 첫 번째 항목은 ‘사람’ 클래스를 나타내는 90% 신뢰도의 class_id=0입니다.

3. results.imgs는 탐지 결과 레이블이 포함된 이미지입니다.
4. results.save(‘폴더’)는 탐지 결과 이미지를 폴더에 저장합니다.
다음은 유형별 차량 수를 계산하는 코드 스니펫입니다.
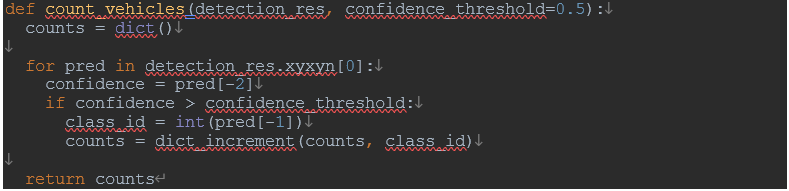
카운팅 코드를 사용하여 훈련된 고속도로 차량 감지 모델을 YOLO 사전 훈련된 기본 모델과 함께 비교해 보겠습니다.
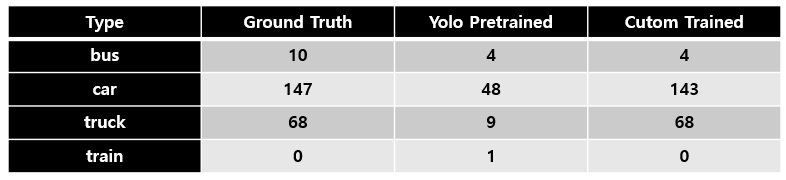
커스텀 모델이 100개 미만의 이미지로 꽤 잘 작동했음을 알 수 있습니다. 멋지네요!
결론
사실 제대로 교통량을 측정하기 위해서는 이것만으로는 부족 합니다. 모델이 비디오 이미지 스트림을 처리하는 경우 중복으로 차량을 계산할 수 있습니다. 정확하게 계산하려면 다양한 프레임에 있는 동일한 차량으로 추적 (tracking)해야 합니다. 이 문제의 해결 방법은 다른 글로 알려 드리겠습니다. 다른 문제는 현재 모델이 낮에 이미지를 촬영하는 고속도로 감시 카메라의 고정 위치에서의 데이터 셋으로 편향되어 있다는 것입니다. 모델을 균형있고 다양한 데이터를 처리할 수 있게 만들려면 더 다양한 데이터 셋으로 모델을 훈련해야 합니다. 이 글을 통해서 그 방법을 알 수 있으셨기를 바랍니다.
Reference
- Source code for converting and generating YOLO V5 formats as well as all other plotting functions can be found in this Colab notebook.
- The sample dataset used came from AI Hub dataset number 30743. The converted YOLO annotation files are found in this git repository.