
Most of the deep learning models are open source, so if you are a developer with knowledge in the field of artificial intelligence, you can make use of the models without difficulty by reading related papers and finding and running the implemented source on GitHub. What determines the performance of a deep learning model is the set of weight values of the model learned through training.
Training a deep learning model requires hundreds, thousands, and even millions of data point. Manually processing all the data is wasteful, labor-intensive, repetitive, and inefficient.
For efficient data processing, an automation model that has been pre-trained is used to label the data first, and then reviewed and fixed by humans-in-the-loop as the second step.
If you use the auto-labeling model, you can focus on improving the quality of data by reducing the resources required for the initial annotation and paying more attention on reviewing and fixing the annotation errors in the second phase.
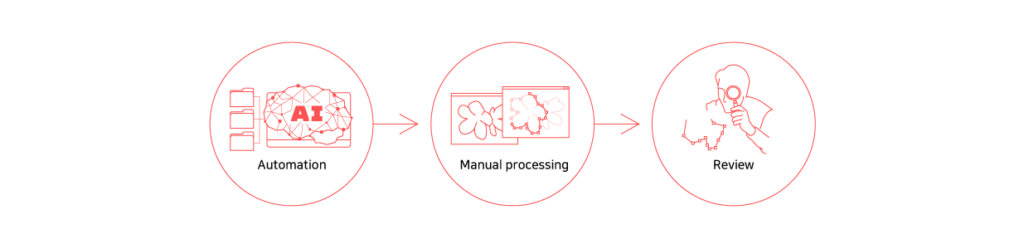
Automation Model
If you are not in the field of artificial intelligence data processing, the term “data processing automation model” may seem unfamiliar and ambiguous in its meaning. This is because data is processed to train a deep learning model and using a deep learning model to process this data sounds like the chicken-and-egg problem. In fact, the chicken-and-egg problem is a good way to think about the automation model that auto-labels the data and the model trained with the preprocessed data. The difference is that the automation model that does the preliminary auto-labeling is trained with relatively limited data to achieve ‘good enough’ performance in a short time. On the other hand, the model trained for production use needs to have the best possible performance so more training data is used, together with various hyper-parameters optimization, and numerous tests over a long period of time.
Currently, about 80% of the processing projects carried out by Testworks are related to image-based data, and automation models for image data are developed and deployed to improve productivity and quality. In the case of text or voice data, customized voice transcription tools are used.
The Status of Automation Models
TestWorks has developed an automation model that can recognize approximately 260 objects in 20 categories in 7 fields such as autonomous driving, pedestrian walking, medical imaging, and security.
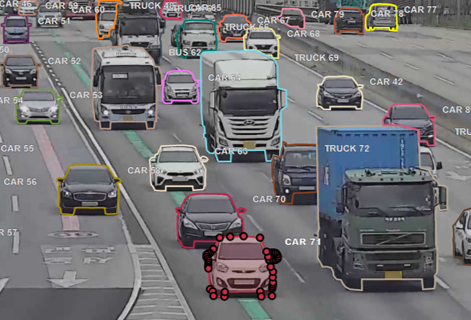
1. Object Detection
The object detection model is a model that finds the type of object and its location based on a rectangle grid and draws a bounding box around the target object as shown in our blackolive screen below.
The Object Detection model consists of two modules: a CNN-based classification model and a localization model that detects the location of an object. The automation model can be a 1-Stage Detector or a 2-Stage Detector depending on how the two modules are configured.

The 2-Stage Detector is slow but has high accuracy, and the 1-Stage Detector is fast but has a relatively low-accuracy model.
Representative object recognition models
– 2-Stage Detector: Fast RCNN, Faster RCNN, FPN (Feature Pyramid Network)
– 1-Stage Detector: YOLO, SSD (Single Shot MultiBox Detector), RetinaNet, CenterNet
2. Semantic Segmentation
Semantic segmentation refers to segmenting objects of an image into meaningful units. The prediction is done at the pixel level. The image on the left shows the areas where the disabled can move. The result is obtained by applying an automation model to the images collected through the “Sidewalk Image AI Training Data” project. Testworks was the leading company of the project which is sponsored by the National Intelligence Service (NIA). This type of prediction cannot be done by an object detection model which classifies objects in the form of bounding boxes.

Representative Semantic Segmentation Models
– Fully Convolutional Network (FCN), U-Net, DeepLab, Mask RCNN
3. Key-Point
During the 2020 NIA “Sign Language Image AI Data” construction project, data for sign language recognition was labeled for human face, body, and fingers. For sign language recognition, it is necessary to process continuous frames (movies) for the duration of 10 seconds, rather than one or two still images. For example, for a video at 30 fps per second, you need to work with 300 images, so automation is absolutely necessary.
Although there are not many models that can extract key-points from face, body, and fingers, for sign language image data construction project, the preliminary auto-labeling is done using the Openpose model that is developed and managed by CMU (Carnegie Mellon University).
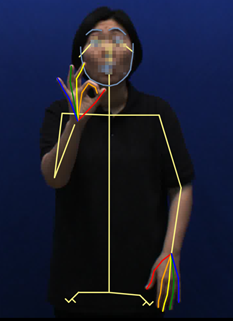
However, there are times when finger key-point extraction could not be done properly when the left and right hands overlap. In such cases, we used different algorithms like Kalman filter to correct the problems.
4. Semi-Auto Polygon Labeling
When annotating polygons, if the object type has a similar domain to that of the previously developed model, the preliminary labeling can be performed using the automated model. If not, annotators must manually draw the object boundaries to conduct polygon annotation. This can be a daunting task that takes more than five minutes for a single object, even for experienced annotators.
Semi-auto polygon labeling can reduce the processing time. When the user selects the target object in a rectangular shape, it automatically separates the background and annotates the foreground object into polygons.


Using the Salient Object Detection (SOD) model, it is possible to find the most important and attention-grabbing object in an image and segment that whole object by following its contour line.

Representative SOD models
– BASNet, U2Net
5. De-Identification
When constructing a dataset for artificial intelligence, one of the concerns is whether personal information is included in the data. Autonomous driving-related datasets that include a lot of people and vehicles should pay particular attention to de-identification of personal information. This is because, if an issue related to personal information arises, not only the data but also the model trained using the data may become liable.
Testworks uses an automation model to detect a person’s face and license plate, and de-identifies personal information by blurring the identified objects.

The current de-identification method is either blurring or pixelating the target which changes the pixels so that humans cannot recognize them. However, these methods have disadvantages in some cases when the anonymized objects are needed for training. Thus, if these objects are altered, the data cannot be used at all.
To compensate for these shortcomings, Testworks is researching a de-identification solution that can be used for these models without damaging the image, using GAN with the goal of making it available in the first half of next year (2022). ( Refer to the blog post “Portrait of the Data Age, Advances in De-identification Technology ” [ii] )
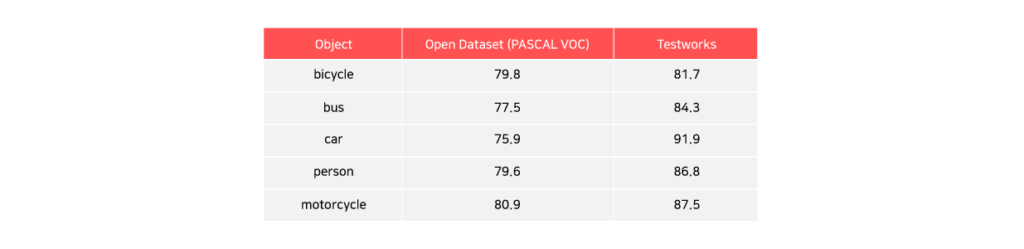
Model performance comparison example
Regarding model performance, we train our deep learning models using data collected and processed from several projects after they are bootstrapped using existing weights. This process is known as ‘transfer learning’. Due to this, our model shows better performance than other public models. The table below shows performance comparison for major classes of Faster RCNN, a benchmark model for object detection.
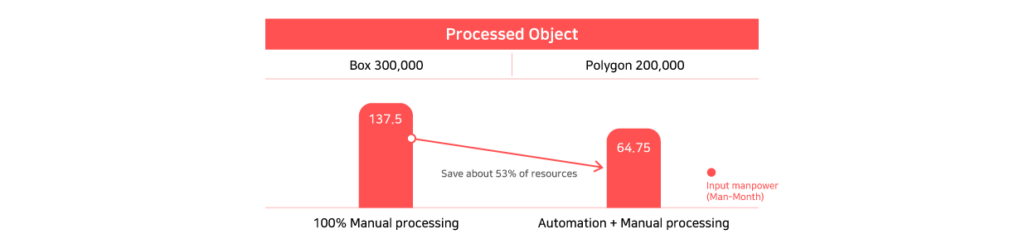
Effect of applying automation model
By applying the automation model, it is possible to save about 53% of resources compared to full-scale manual labeling.
Conclusion
There is a saying in statistics, “If you put garbage in, garbage comes out”. This means that if you use bad data, the model will not perform well either. Although AI models are improved to some extent as they develop, a good dataset is still an essential element for creating high-performance deep learning models. To create a large amount of high-quality data, an auto labeling automation model is essential, and with the development of deep learning models, auto-labeling will become easier and easier.
Recently, research is ongoing not only on automating annotation but also on the review process. For instance, you can verify annotation results by cross validating the predictions made by multiple models on the same dataset. Another active area of research is active learning where the confidence value of the object recognition model during prediction is used to notify the user if it is below the threshold value so that only the needed data are reviewed and re-labeled. All such development shows that automation in AI data processing is far from done and we need to continue to keep abreast of the latest research development.
[i] Image excerpt from article U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
[ii] Portrait of the data age, development of de-identification technology, Testworks Hyungbok Kim

Jeonghyun Im
Senior Researcher, AI Model Development Team
Chosun University, B.S. in Computer Engineering,
(Former) Mobile Reader Senior Researcher, Participated in Samsung Keis development
After developing Windows applications for more than 15 years, he changed his field of interest to artificial intelligence and started developing a geological analysis system using a deep learning model.