
사람과 동물의 가장 큰 차이점은 무엇일까요?
세심한 동작이 가능한 손, 보이지 않는 무언가를 믿을 수 있는 신앙심, 실존하지 않는 개념을 약속하고 지키는 법 등…
얼핏 생각하기에도 사람과 동물은 다른 부분이 너무나 많습니다. 그러나 그 중에서도 결정적으로 다른 부분이 하나 있습니다.
바로 ‘언어’입니다.
언어는 인류가 동물과 분리되어 대에 걸쳐 지식을 전달하고 문명을 쌓아 올릴 수 있게 만든 핵심 요소입니다. 모든 인간은 언어를 통해 서로 소통을 하며 지식을 축적합니다. 태어나면서부터 주변인을 따라 옹알이를 하고 처음으로 단어를 뱉는 순간을 기대하는 것은 동물에게는 없는 축복일 것입니다.
때문에 사람과 흡사한 지능을 표방하는 ‘인공지능’ 분야에서 자연어 처리 분야는 빠질 수 없는 큰 부분을 차지하고 있습니다. 언어는 그야말로 가장 사람 다운 행동입니다. 이 자연어 처리가 정복 된다는 것은 진정한 인공지능을 위해서는 반드시 필요한 부분이며, 전 세계의 많은 거대 자본이 이를 위해 투자되고 있습니다.
피할 수 없는 그것, 트랜스포머
자연어 처리(Natural Language Processing – NLP)는 인공지능 모델을 활용하여 사람의 언어를 모방하는 모든 분야를 말합니다. AI 분야에서 큰 한 축을 담당하는 만큼 많은 사람들이 연구하고 있으며, 새로운 연구자 또한 계속해서 나오고 있습니다. 그리고 지금 단계에서, 딥러닝 초급자를 넘어 자연어 처리를 공부하고자 하는 모든 사람들에게 피할 수 없는 관문 같은 키워드가 있습니다.
바로 트랜스포머 입니다.
일반적으로 트랜스포머 하면 무엇이 생각나시나요? 저는 스크린에서 화려하게 도시를 깨부수던 변신 로봇들이 생각납니다. 라디오로 의사소통하던 범블비, 목소리가 끝내주는 옵티머스 프라임, 악당이지만 멋있던 스타스크림 등…이렇게 대부분의 사람들은 트랜스포머라는 단어를 듣는 순간 저처럼 변신 로봇들이 눈을 즐겁게 해주던 장면이 떠오를 것입니다. 그러나 자연어 처리를 공부하는 사람에게 트랜스포머라는 단어가 귀에 들어오면 옵티머스 프라임의 강렬한 목소리보다도 다른 것이 먼저 떠오르게 마련입니다. 바로 지겹게 반복하여 다루었을 트랜스포머라는 자연어 처리 모델입니다.

목소리가 너무 좋은 옵티머스 프라임! 그러나 제가 이야기할 트랜스포머는 이 로봇이 아닙니다.
트랜스포머는 2017년 Attention Is All You Need라는 기념비적인 자연어 처리 논문에서 처음 제안 되었습니다. 이 논문에서 제안 된 트랜스포머 구조는 현재 사용되는 모든 자연어 처리 관련 모델의 선조격이라 해도 과언이 아닙니다. 등장 이후 자연어 처리 분야를 평정했을 만큼 트랜스포머는 강력했으며, 언어적 특징을 가장 잘 고려한 모델이라고도 볼 수 있습니다. 트랜스포머가 낳은 수많은 자식들이 현재 자연어 처리 분야를 지배하고 있는 만큼, 자연어 처리를 공부하는 사람에게 트랜스포머는 하나하나 꼭꼭 씹어서 소화해야만 하는 모델이라고 볼 수 있습니다.
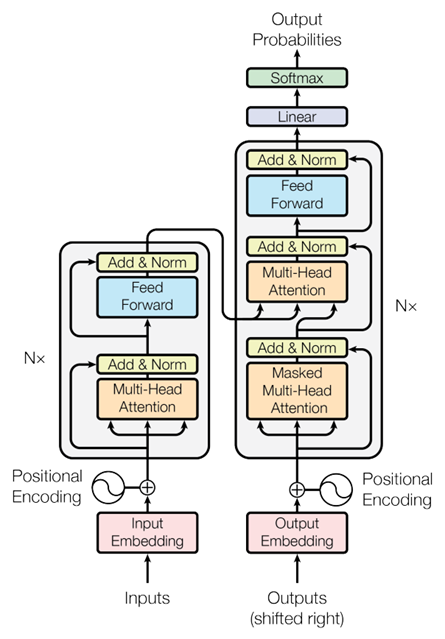
출처: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010
논문의 제목을 그대로 해석해 보면 어떤 가요? Attention이야말로 모든 것이라고 말하고 있습니다. 트랜스포머가 자연어 분야를 평정한 데에는 바로 이 Attention을 적극적으로 기용한 데에 있습니다. 자연어 모델을 다룰 때에는 트랜스포머 못지않게 이 Attention에 대해 자주 논할 수 밖에 없습니다. 그 중에서도 트랜스포머의 핵심은 self-attention에 있습니다.
Attention이 의미하는 것은 ‘강조’입니다. 일반적으로 어떤 말을 통해 의미를 전달하고자 할 때 핵심은 사실 한 두 문장, 혹은 한 두 단어에 압축 되어 있는 경우가 많습니다. 여러 단어들이 함께 나열되어 하나의 글을 이루어도, 각각의 중요도가 서로 다르다는 것은 구태여 언급하지 않아도 모두가 알고 있습니다. 트랜스포머는 이러한 언어적 특징을 중점적으로 다루었습니다. 모델에게 언어를 가르칠 때 문장 내에서 단어 간 중요도에 차이가 있음을 ‘강하게’ 알려준 것입니다. 그냥 attention이 아닌 self-attention인 이유는 스스로가 스스로를 강조하기 때문입니다. 이해를 돕기 위해 예시를 한번 들어보겠습니다.
‘The man cross the river that is large with a small boat’
위 문장을 살펴 볼까요? 남자가 강을 건너는 주체이고, 그 강은 큰 강이며, 남자가 탄 보트는 작다는 것을 즉시 파악할 수 있습니다. 하지만 학습되지 않은 언어모델은 boat라는 단어와 small이라는 단어가 무슨 관계인지, large라는 단어와 river라는 단어가 무슨 관계인지, cross와 man은 무슨 관계인지 전혀 알지 못합니다. self-attention은 이런 이해를 할 수 있게 도와줍니다. 각 단어 입장에서 어떤 부분을 강조해야 할지 알려주는 것입니다.
man이라는 단어 입장에서 위 문장을 다시 한번 살펴보겠습니다. 나열된 단어들 중에서 man이 좀 더 주의 깊게 살펴보아야 할 단어들은 무엇일까요? 제 생각에는 the보다는 cross가, large보다는 boat가, a보다는 river가 더 중요할 것 같습니다. self-attention은 이처럼 문장 내에서 한 단어가 어떤 단어를 좀 더 주위 깊게 살펴봐야 하는지, 다시 말해 나열된 단어 간에 서로 어떤 연관성이 있는지를 알려주는 역할을 합니다. 이를 모델의 입력 입장에서 보면 자기 자신이 자기 자신을 참조하고 강조하는 형태가 될 것입니다. self-attention이라고 부르는 이유가 어느 정도 이해가 되시나요?
트랜스포머 모델에서 파악해야 할 것은 self-attention만이 아닙니다. 나열하기도 어려울 만큼 다양한 기능이 한데 어우러져 트랜스포머라는 거대한 구조를 이루고 있습니다. 그러나 이를 하나하나 자세히 설명하고자 하면 책을 써야 할 만큼 길어질 것입니다. 실은 self-attention만 해도 훨씬 더 긴 설명을 해야 합니다!
트랜스포머의 자식들, BERT와 GPT
자연어 처리에 조금이라도 관심이 있는 분이라면 트랜스포머 이전에 BERT와 GPT를 먼저 들어봤을지도 모르겠습니다. 자연어 관련 핫이슈로, 뉴스에도 심심치 않게 BERT와 GPT는 키워드로 등장하곤 합니다. 그 유명한 BERT와 GPT가 사실은 트랜스포머의 자식들인 것을 알고 계셨나요? 만약 여러분이 트랜스포머를 이해하는데 성공했다면 축하합니다! 다음은 BERT와 GPT 차례 입니다. 불행 중 다행으로 이 둘은 트랜스포머를 이해하고 있다면, 그 구조 파악은 어렵지 않을 것입니다.
BERT(Bidrectional Encoder Representations from Transformers)와, GPT(Generative Pretrained Transformer)는 각각 Google과 OpenAI에서 만든 자연어 모델입니다. BERT는 트랜스포머의 인코더를, GPT는 트랜스포머의 디코더를 분리해 각각 독자적인 모델로 발전시켰습니다. 그야말로 트랜스포머를 반으로 갈라 BERT와 GPT가 탄생한 것입니다. 그리고 이 둘은 현재 자연어처리 분야를 양분하고 있다고 해도 과언이 아닙니다. BERT와 GPT의 다양한 버전들이 전 세계 곳곳에서 실제로 활약하고 있습니다.
더 크게 더 많이
최근 GPT가 1, 2를 넘어 3까지 버전업이 되었습니다. 당연하게도 1보단 2가, 2보단 GPT3가 성능이 더 뛰어납니다. 그러나 실은, GPT1, 2, 3는 모두 같은 모델이나 다름없다는 것을 알고 계시나요? GPT2, GPT3 모두 기본적인 GPT의 구조를 그대로 사용하고 있는 것입니다. OpenAI가 GPT의 버전을 쌓아 올리면서 가져간 핵심적인 차이는 ‘크기’입니다. GPT1보다 GPT2가, GPT2보다 GPT3가 훨씬 거대한 모델인 것입니다. GPT3에 이르러서는 그 크기가 너무나 거대해 여타 초거대 기업조차도 학습 환경을 구성하기 어려울 정도입니다. 그 파라미터 수가 사람 뇌의 뉴런 개수 보다 많다고 하니까요. 이게 끝이 아닙니다! Google은 최근 GPT3의 대항마로 PaLM이라는 언어 모델을 발표했는데, 그 규모는 GPT3보다도 훨씬 거대해서 파라미터 수가 5400억 개나 된다고 합니다. 이 모델 학습을 위해서 얼마나 많은 컴퓨팅 파워가 필요한지 짐작도 어려운 수준입니다.
더 큰 모델과 더 큰 학습 셋으로 더 나은 모델을 만드는 것은 비단 자연어 분야에 한정돼 있지 않습니다. 모든 AI 회사는 업계 트렌드인 ‘더 크게 더 많이’를 따르기 위해 데이터, 그리고 GPU 확보에 혈안이 되어 있습니다. 그중에서도 자연어 분야는 특히 그 경향성이 더 강하다고 볼 수 있습니다. 일류기업과 같이 막대한 자본을 투입할 수 없는 소규모 업체 입장에서는 이런 부분이 현실적인 장벽이 되어 이상을 가로막는 법입니다. 그렇다고 중소규모 업체들의 중요성이 떨어지는 것은 아닙니다. 거대한 손이 영향을 끼치지 못하는 디테일한 부분들은 작은 손들이 더욱 잘 해낼 수 있습니다. 이런 디테일한 부분들에 최신 기술을 접목시키는 것이 우리 연구자들의 역할일지도 모르겠습니다.

우상명
연구원, AI 연구 개발팀
성균관대학교 전자전기공학/컴퓨터공학 학사
성균관대학교 전자전기컴퓨터공학 석사
머신러닝/정형 데이터 연구를 수행하였고, 현재는 테스트웍스 AI 연구 개발팀에서 근무 중이며, 자연어처리 및 Vison-Language Proccessing을 주로 연구하고 있다.