
최근 구글이 새 언어 모델 PaLM(Pathways Language Model)을 공개했습니다. 구글, 오픈 AI, 마이크로소프트 등의 공룡 기업들은 더 뛰어난 모델을 만들기 위해서 서로 경쟁하고 있습니다. 그리고 이 과정에서 발표되는 모델들은 다른 기업들은 감히 시도조차 하기 어려울 정도로 점점 거대해지고 있죠. 이번에 공개된 PaLM 역시 파라미터 수가 GPT3의 3배인 5400억 개라고 하니, 그야말로 초거대 인공지능이라고 부를만합니다.
구글이 공개한 PaLM에 대한 리포트를 보면서, 제가 제일 흥미롭게 보았던 부분은 모델의 성능에 대한 것이었습니다. 크게 두 가지가 있는데 하나는 PaLM이 기존 다른 모든 모델의 성능을 초월하고 있다는 것, 다른 하나는 처음으로 특정 평가 지표에서 인간을 초월한 성능을 보였다는 것입니다. 이 얘기를 들으면 어떤 생각이 드시나요?
와! 드디어 사람을 뛰어넘었다니! 스카이넷이 멀지 않았구나! 매트릭스를 대비하자!
결론부터 말하자면 저는 아직 한참 멀었다고 생각합니다. 물론 그 한참이 제 기준이라 어쩌면 다른 분들의 입장에서는 금방일지도 모르겠습니다.
이번에 이야기해 볼 내용은 자연어 처리 모델의 평가는 어떻게 이루어지는지에 대한 내용입니다. 그중에서도 특히, 자연어 생성에 대한 평가를 이야기해 보려고 합니다. 자연어 처리 모델의 목적은 여러 가지가 있지만, 그중에서도 가장 어려운 것은 자연어 생성이라고 할 수 있습니다. 그야말로 말하는 것 그 자체이기 때문이죠.
사람 중에서는 누가 말을 제일 잘해?
사람에게 자연어 생성이란 무엇일까요? 낯선 키워드로 말을 했을 뿐이지, 사실 어렵지 않습니다. 내 생각을 글로 표현하고 남에게 전달하는 것, 소설, 대화, 산문, 시, 기사 등… 모든 글자로 이루어진 것이 바로 자연어 생성입니다. 그럼 여기서 한번 질문을 해보겠습니다.
어떤 사람이 자연어 생성을 제일 잘해?
어떻게 생각하시나요? 누군가 이렇게 이야기할 수 있을 것 같습니다. 역시 셰익스피어지! 아냐 헤밍웨이가 최고야! 많은 분들이 끄덕일 것입니다. 그렇지 그 정도면 인정할 수 있지 하면서요. 그런데 갑자기 어떤 사람이 말을 합니다. 아니야 나는 두보와 이백이 제일 잘한다고 생각해. 마찬가지입니다. 많은 사람들이 오오 그럴 수 있지 하면서 고개를 끄덕입니다. 그럼 여기서 질문이 있습니다. 두보와 이백 중에서는 누가 더 뛰어난 자연어 생성 능력을 가졌나요? 셰익스피어와 헤밍웨이 중에서는 누가 더 뛰어난가요? 의견이 분분해질 것입니다. 각자 생각하는 바가 다 다르니까요.
그럼 어느 자연어 모델이 말을 제일 잘해?
자연어 처리(Natural Language Processing – NLP)는 인공지능 모델을 활용하여 사람의 언어를 모방하는 모든 분야를 말합니다. 그리고 자연어 생성은 자연어 처리의 세부분야 중 하나입니다. 여기서 핵심은 바로 ‘사람의 언어를 모방하는 것’입니다. 자연어 생성 역시 다르지 않습니다. 따라서 평가 지표 역시 사람의 자연어 생성과 같은 맥락에서 이루어져야 합니다. 그럼 사람의 경우엔 어땠나요? 누가 가장 뛰어난 작문가인지 객관적인 비교가 가능했나요? 제 생각에 답은 ‘아니오’입니다. 누가 쓴 시가 더 뛰어난지, 누구의 소설이 더 훌륭한지는 개개인마다 생각이 다 다를 수밖에 없습니다.
모델의 자연어 생성 역시 마찬가지입니다. GPT3가 소설을 쓰든, PaLM이 시를 쓰든 어느 정도 수준 이상에 도달한 상황에서는 둘 중 누가 더 뛰어난가를 평가하는 것은 개인의 주관에 달려있습니다. 이런 특징 때문에 자연어 처리 중에서도 자연어 생성은 누가 우열인지 평가하기가 어렵습니다. 그럼에도 연구자들은 자신의 연구 성과를 정량적으로 평가하기 위한 지표들을 만들었습니다. 비록 이 지표들이 모델의 성능을 온전히 대표한다고 보긴 어렵지만, 성능의 경향성을 보여주고 있음은 틀림없습니다.
당부드리고 싶은 것은, 지금 이야기하는 내용은 자연어 생성에 관련된 것이지 자연어 처리 전체에 대한 내용이 아니라는 것입니다. 자연어 생성이 아닌 다른 부분에서는 비교적 모델 성능이 객관적으로 비교되는 지표가 많이 있습니다!
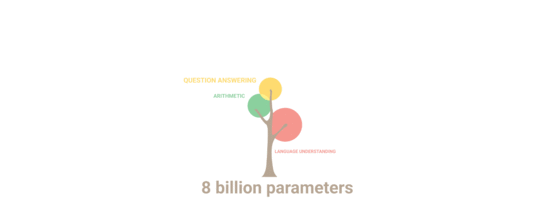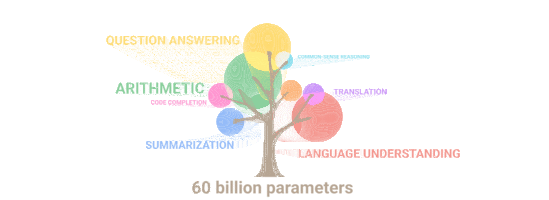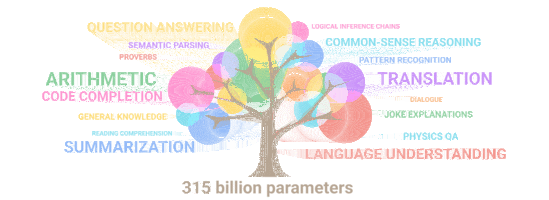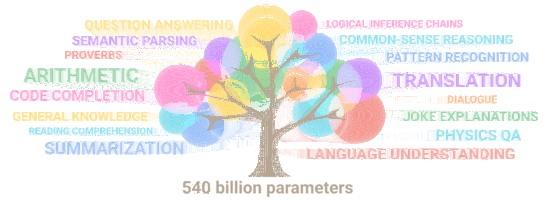
5400억 개의 파라미터를 가진 PaLM이 뛰어난 성능을 보이는 자연어 처리 항목들.
거의 모든 분야가 포함되어 있습니다.
자연어 생성의 성능 비교 방법들
작문이라는 것은 고차원적인 생각을 2차원 평면의 글씨에 담아내는 것입니다. 반드시 적절한 정보의 압축이 이루어져야만 하죠. 때문에 글자만으로도 자연스럽게 고차원적인 생각을 원복시켜주는 명문을 쓰는 작가들은 반드시 이름을 날리게 마련입니다. 이처럼 사람도 어려워하는 일을 딥러닝 모델이 할 수 있게 연구한다니 참 어렵고 멋진 일이 아닐 수 없습니다. 많은 연구자들은 좀 더 나은 자연어 생성을 위해 고민하고, 이를 평가할 수 있는 지표들을 만들어 냈습니다. 그리고 이 지표들은 불완전하더라도 자연어 생성에 대한 모델의 성능을 나타내고 있습니다. 대표적인 평가 지표들이 어떤 것이 있는지 한번 알아보겠습니다.
PPL(Perplexity)
자연어 생성 모델의 성능 지표를 이해하기 위해서는 자연어 생성 모델의 기본적인 동작부터 이해할 필요가 있습니다. 현재 트랜스포머 기반의 거의 모든 자연어 생성 모델은 문장을 만들 때 한 번에 완성된 상태로 결과물을 내지 않습니다. 처음부터 토큰을 한 개씩 순차적으로 생성을 하게 되죠. 여기서 토큰이란 글자보단 크고 단어보다는 작은 어떤 단위입니다. 먼저 한 토큰을 생성하고, 그 토큰을 기반으로 다음 토큰을 생성합니다. 이 과정을 누적해가면서 진행하고, 모델이 문장의 끝을 알리는 토큰을 생성하면 비로소 문장 생성이 완료됩니다.
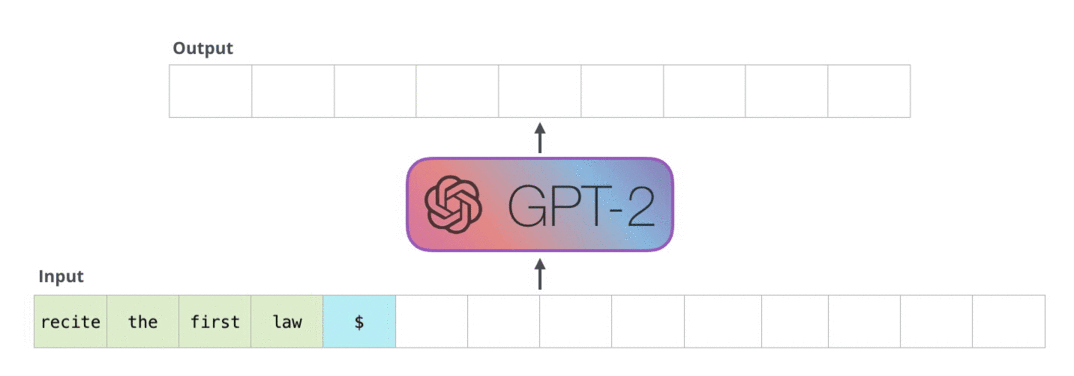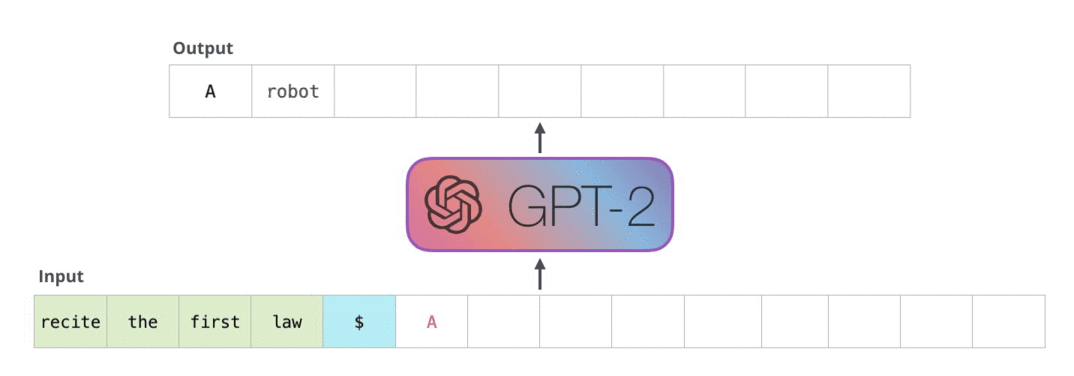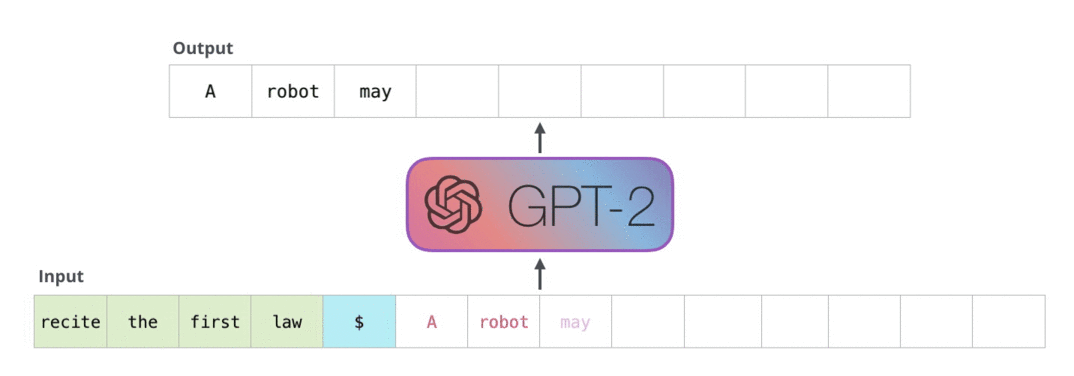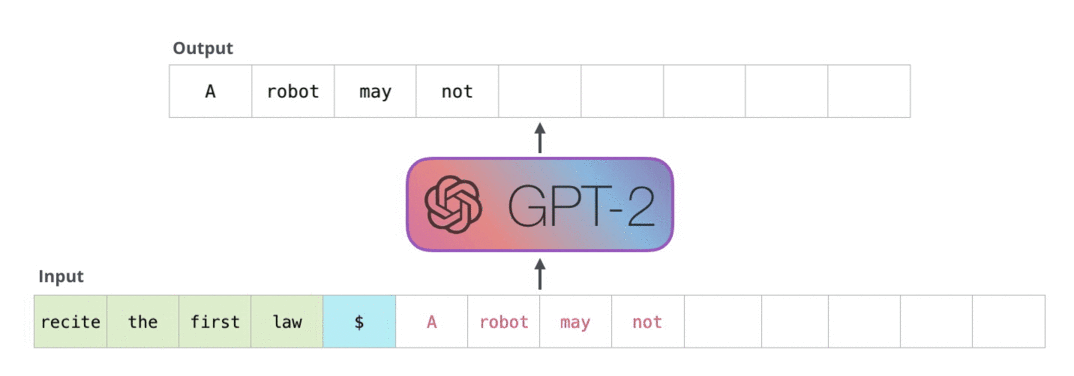
GPT2가 자연어를 생성하는 과정.
반복적으로 생성한 토큰을 누적하면서 다음 토큰을 생성한다.
이런 과정이 반복되면서 문장이 완성될 때, 각 토큰은 확률적으로 선택됩니다. 수만 가지 경우의 토큰 중 가장 확률이 큰 한 개의 토큰이 선택되는 것입니다. 그리고 Perplexity는 문장이 완성될 때까지 선택된 토큰들의 누적된 확률을 기반으로 계산한 값입니다. N개의 토큰 {w1, w2, w3, w4, ···, wN}으로 구성된 문장의 Perplexity의 계산식은 아래와 같습니다.
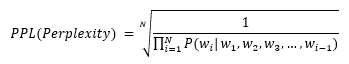
이해가 되나요? Perplexity가 의미하는 바는 사실 모델의 성능과 직결된다고 보기는 어렵습니다. 당혹감, 혼란 등의 단어가 가진 의미 그대로 모델이 정답을 결정할 때 얼마나 헷갈렸는가를 나타내는 지표라고 보시면 될 것 같습니다. Perplexity가 낮을수록 모델이 덜 헷갈린 상태로 확신을 가지고 답을 냈다는 뜻이고, 그만큼 특정한 방향으로 학습이 잘 됐다는 얘기로 볼 수 있습니다. 만약 잘못된 방향으로 모델이 학습되었다면 낮은 perplexity와 함께 오답을 출력하게 될 것입니다.
BLEU(Bilingual Evaluation Understudy)
BLEU는 가장 범용적으로 사용되고 비교적 신뢰도도 높은 편이기에 많은 자연어 처리 모델이 생성 평가를 할 때 사용하는 방법입니다. 물론 완벽하진 않기에 BLEU를 기반으로 개선시킨 다양한 측정 방법들이 연구되고 있지만 그중 원조인 BLEU는 여전히 사랑받고 있습니다. BLEU를 수식으로 표현하면 아래와 같습니다.

위 수식은 크게 두 부분으로 이루어져 있습니다. 왼쪽 min으로 묶인 Brevity penalty와 오른쪽의 precision입니다. 먼저 왼쪽의 Brevity penalty가 의미하는 것은 문장 길이에 대한 보정입니다. 우리가 예상한 것에 비해서 문장 길이가 지나치게 짧다면 그건 좋은 결과라고 보지 않는 것이죠. 이건 모델이 문장 생성을 중간에 그만두는 경우도 고려한 좋은 보정이라고 할 수 있습니다. 그리고 오른쪽의 precision입니다. 이것을 설명하려면 n-gram을 건너 뛸 수가 없습니다. n-gram은 그냥 연속된 n개의 토큰을 n-gram이라고 지칭합니다. 1-gram이면 1개, 2-gram이면 2개, 3-gram이면 3개의 연속된 토큰을 말하는 것이지요. BLEU는 1~4-gram이 타깃 문장 대비 얼마나 많이 일치하는지를 계산하는 것이 핵심 입니다. 이 두 가지가 합쳐져서 BLEU가 측정됩니다.
사실 BLEU는 위에 이야기한 것 보다 설명해야 할 요소들이 더 많이 포함되어 있습니다. 그렇기 때문에 BLEU가 가장 범용적인 지표 중 하나가 되고, 이를 기반으로 많은 지표들이 파생되는 것입니다. 이를 굳이 설명하지 않고 BLEU를 짧게 정리하자면, ‘목표로 하는 문장과 모델이 생성한 문장이 일치하는 정도’를 수치화 한 지표라고 할 수 있겠네요. 이러한 BLEU도 명백한 한계가 있습니다. n-gram이 일치하는 것만 확인하기 때문에 단어 간의 유사성이 고려되지 않는 것입니다. 같은 의미의 단어라도 다른 단어가 나올 경우 점수가 낮게 측정되므로 전체적인 문장의 의미가 잘 반영된 지표라고 보기는 어렵습니다.
METEOR(Metric for Evaluation of Translation with Explicit ORdering)
METEOR은 BLEU로부터 파생된 평가 방법들 중 하나입니다. BLEU의 불완전함을 보완하고 더 나은 지표를 설계하고자 한 것입니다. BLEU와의 가장 큰 차이점은 precision만 고려하는 BLEU와는 달리 recall도 함께 고려했다는 것입니다. 그리고 다른 가중치를 적용한 이 둘의 조화평균을 성능 계산에 활용하고 있습니다. 또 오답에 대해 별도의 penalty를 부과하는 방식을 채택하거나, 여러 단어나 구 등을 정답으로 처리하는 등 여러 방면으로 BLEU를 보완하고자 했습니다.
SSA(Sensible and Specificity Average)
SSA는 구글에서 발표한 자율 발화 모델에 대한 평가 지표입니다. 사람처럼 말하는 것이 목표인 모델을 평가할 때 사용하는 방법인데, 기계적인 방법 말고도 이런 방식도 있다는 것을 이야기하고자 내용에 담았습니다. 수식들을 최대한 덜어내고 쉽게 설명하려고 했던 다른 측정 방법과는 달리 SA는 지극히 사람 중심적이고 인문학(?)적 입니다. SSA는 사람이 직접 자율 발화 모델과 대화를 하며 점수를 평가하는 것인데, Sensibleness와 Specificity의 두 가지 항목 외엔 점수 측정 요소가 없습니다. Sensibleness는 사람의 말에 대한 봇의 답변이 합리적인지를, Specificity는 해당 답변이 단답형이 아닌 구체적인 답변인지를 나타냅니다. 각 점수는 오직 그렇다 아니다 두 가지만 고를 수 있고, 각각을 1과 0으로 계산하여 평균 낸 것이 바로 SSA입니다. 개인의 주관을 배제하기 위해 최대한 평가 지표를 간단하게 만들었다고는 해도, 겨우 이런 내용이 실제 모델 평가를 하는데 적절한 방법이라 생각이 되나요? 구글은 되게 만들었습니다. 잘 교육된 수 많은 사람들에게 자기들이 만든 모델에 대한 SSA를 측정하도록 했거든요. 뿐만 아니라 최근에는 SSA의 업그레이드 버전이 나오기도 했습니다!
어떤 평가 방법이 최고일까?
자연어 생성을 평가하는 지표들은 위에서 나열한 것 말고도 여러 가지가 있고, 앞으로도 계속해서 생겨날 것입니다. 연구자들이 각자 지향하는 바에 맞도록 평가 방법들을 끊임없이 고안해 내고 있기 때문입니다. 이런 자연어 생성 평가 지표들 중에 널리 사용되는 것은 있어도 왕도는 없습니다. 심지어 유명하다고 해서 해당 평가 지표가 가장 정확하다고 말하기도 어렵습니다. (사실, GEM이라는 현재로썬 가장 신뢰도가 높은 지표가 있지만 마찬가지로 모든 영역을 커버하진 못합니다.) 그래서인지 자연어 생성 모델을 소개하는 논문들은 다른 자연어 처리 분야나 이미지 분야에 비해서 정량적 성과를 덜 강조하는 편입니다. 혹은 여러 개의 지표들을 내세워 자기 모델의 우수성을 보여주려고 하기도 합니다.
자연어 생성은 자연어 처리 분야의 최종 목표라고 볼 수도 있습니다. 사람처럼 말하고 쓰는 것을 의미하기 때문입니다. 그래서 자연어 분야의 공룡들은 우리 모델이 소설을 이만큼 써! 우리 모델이 만든 뉴스 기사는 사람이 봐도 어색하지 않아! 하는 등으로 생성을 가장 강조하여 내세우곤 합니다. 그렇다면 그들이 주장하는 ‘우리가 만든 모델이 최고야!’가 모두 맞을까요? 저는 ‘글쎄’라고 답하고 싶습니다. 이미 그 정도 규모의 모델들은 평가를 위해 개인의 주관이 들어갈 수밖에 없는 수준에 도달했기 때문입니다. 어쩌면 모델 성능을 말해주는 가장 좋은 지표는 파라미터 개수와 학습한 데이터 양일지도 모릅니다. 으레 더 큰 모델에 더 많은 데이터 셋을 학습 시키면 성능이 좋아지게 마련이니까요. PaLM 이후로도 ‘더 크게 더 많이’하려는 공룡들의 경쟁은 끝나지 않을 것 같습니다.

우상명
연구원, AI 연구 개발팀
성균관대학교 전자전기공학/컴퓨터공학 학사
성균관대학교 전자전기컴퓨터공학 석사
머신러닝/정형 데이터 연구를 수행하였고, 현재는 테스트웍스 AI 연구 개발팀에서 근무 중이며, 자연어처리 및 Vison-Language Proccessing을 주로 연구하고 있다.