
테스트웍스는 인공지능 데이터 전문기업으로 인공지능 산업의 3대 요소 중 하나인 데이터를 보다 생산적으로 구축하기 위한 인공지능 기술을 연구 개발하고 있습니다. 특히, 인공지능 모델을 활용한 자동화 기술을 통해 데이터셋을 구축하는 과정에서 시간과 비용을 줄여, 생산성을 높이고 있습니다.
[AI 데이터셋 구축 과정]
인공지능 모델 학습을 위해 활용되는 데이터셋을 구축하는 과정은[i] 다음과 같습니다.
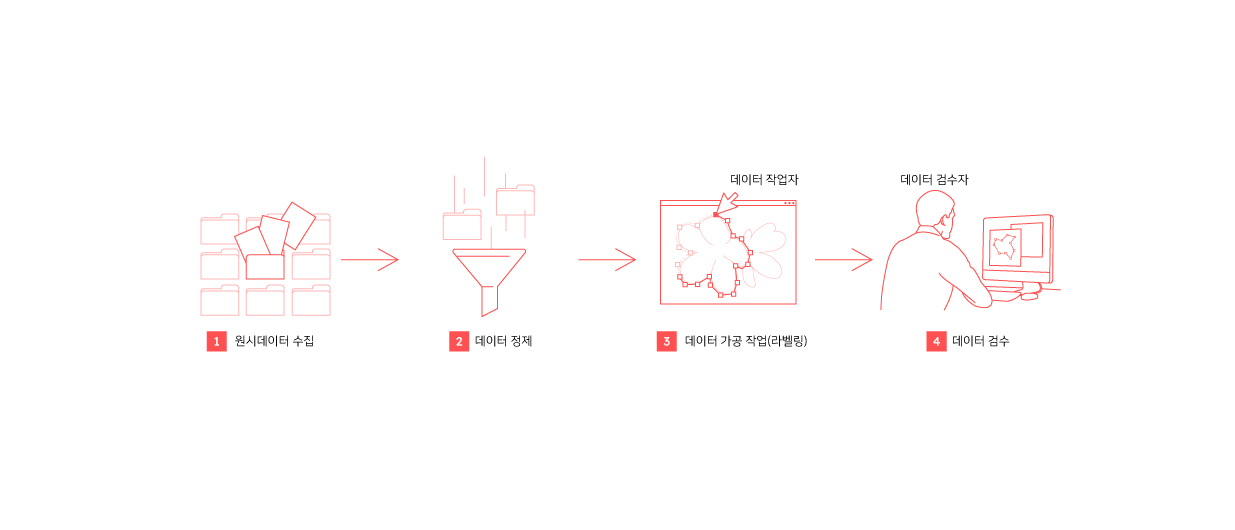
먼저 인공지능 모델 학습에 필요한 이미지, 영상, 오디오, 텍스트 등 원시 데이터를 수집합니다. 그리고 아래와 같은 전처리 과정을 통해서 원시 데이터를 데이터 라벨링을 위한 원천 데이터로 정제합니다.
- 데이터 수집 과정에서 발생하는 오류나 잡음 제거
- 동일한 규격으로 원본 데이터 표준화
- 불필요한 데이터 제거
- 중복 데이터 제거
- 개인정보 보호를 위해서, 데이터 비식별 작업 수행
이후, 아래 그림의 예시와 같이 인공지능 모델이 올바른 결정(분석)을 내릴 수 있도록 원천 데이터에 정답 데이터 값(ground truth)을 입력하는 데이터 라벨링 작업을 진행합니다.

마지막으로, 라벨링된 데이터에 포함된 불완전한 정보를 검수를 통해, 오류가 있는 라벨링 정보를 수정 또는 제거하고, 누락된 라벨링 작업을 추가로 수행하는 작업을 거쳐 데이터셋을 구축합니다.
[AI 학습용 데이터 구축 소요 시간 및 비용]
인공지능 프로젝트에 소요되는 시간 대부분은 데이터를 수집, 정제 및 라벨링 작업에 평균적으로 75%의 비용이 소요됩니다. 이는 인공지능 학습 데이터 구축에 수많은 시간 및 비용이 발생한다는 것을 의미합니다.
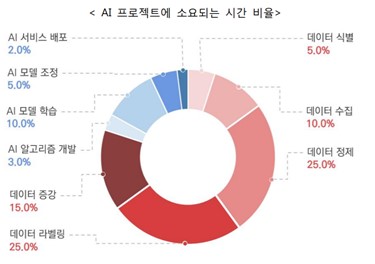
테스트웍스는 이러한 비용 및 시간을 최소화하기 위한 기술을 도입했습니다.
[데이터 가공 비용 절감 및 생산성 향상을 위한 기술 도입]
Python을 활용한 1차 데이터 정제
스마트폰을 통해서 촬영된 데이터의 경우, 사진 내부에 회전 정보까지 포함되어 있어서, 라벨링 작업 수행 시 이미지가 90도 회전된 경우가 존재합니다. 이를 해결하기 위해서 python으로 1차적으로 회전 정보를 제거하는 작업을 수행하여 데이터를 정제해 줌으로써, 작업자들이 라벨링 작업 수행 시 겪을 혼란을 감소시켰습니다.
AI 모델을 활용한 데이터 비식별화
데이터 비식별화 작업 수행 시, 작업자는 비식별화 할 대상 객체를 일일이 확인하며 비식별화 작업을 수행합니다. 비식별화 작업량이 늘어날수록 작업자의 피로도가 증가하며, 비식별 대상 객체를 놓치는 경우가 발생할 수 있습니다. 이러한 문제를 해결하고 작업의 효율성을 높이기 위해 비식별 대상을 학습한 인공지능 모델을 활용하고 있습니다.
먼저, 인공지능 모델이 비식별화 작업을 수행하고, 그 다음에 작업자들이 인공지능 모델이 비식별화 한 작업을 검토 및 수정하는 방식으로 작업자들의 업무 부담을 줄여, 비식별화 작업의 생산성을 높였습니다.
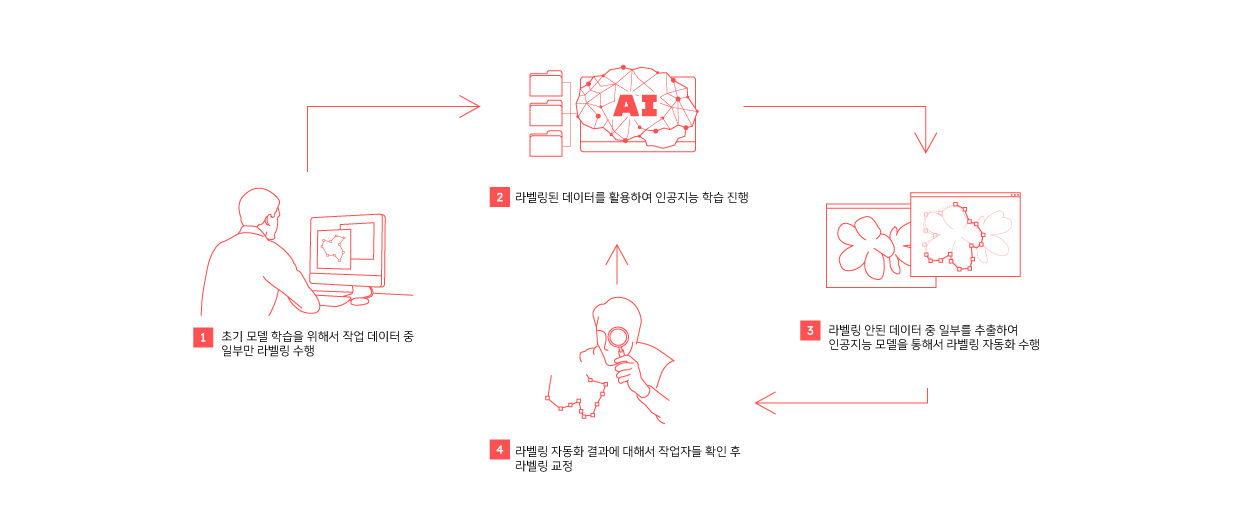
Human in the loop 방식의 데이터 라벨링
데이터 라벨링의 경우에도, 100% 수동으로 진행하지 않습니다.
우선 라벨링 작업을 수행해야 할 전체 데이터셋 중 1~5% 정도의 데이터셋을 수동으로 라벨링 작업을 수행합니다. 그리고 나서 해당 데이터셋을 활용해서 인공지능 모델을 학습시킵니다. 학습한 인공지능 모델을 활용하여, 자동화된 라벨링 결과를 얻습니다.
라벨링이 잘못된 데이터의 경우, 작업자가 검수하여 라벨링 데이터를 교정해 줍니다. 교정 작업이 완료되면, 라벨링되어 축적된 데이터셋을 활용해서 인공지능 모델을 재학습 시킵니다.
라벨링 과정에서 사람이 교정한 데이터셋으로 학습한 인공지능 모델을 활용하여 데이터 라벨링 반자동화 과정을 거침으로써 작업자들의 업무 부담을 줄이면서, 데이터 라벨링의 정확성을 높이고 있습니다.
[마치며]
인공지능 학습을 위한 고품질 데이터셋을 구축하기 위해서 기술의 도입은 비용적인 측면에서 필연적으로 고려하게 되는 요소입니다.
현재까지는 충분한 학습 데이터를 기반으로 수행되는 데이터 라벨링 자동화만을 수행하고 있으나, 도메인에 따라서 학습 데이터 자체가 적은 경우 자동화에 어려움을 겪는 것을 확인했습니다. 이러한 부분을 해결하기 위해서 최근에는 적은 학습 데이터만으로 라벨링을 수행할 수 있도록 few-shot learning 기술이나, 적은 학습 데이터를 증강하는 GAN 기술, active learning 기술을 활용하여 사람의 검수 과정 없이 학습 데이터를 축적해서 모델을 학습하는 auto labeled data training 등을 연구하고 있습니다.
기술을 통한 데이터셋 구축을 통해서 양질의 대규모 데이터셋이 구축되어 인공지능 생태계가 활성화되기를 희망합니다.
[i] NIA – 인공지능 학습용 데이터셋 구축 안내서.pdf 참고
그림 [1] 과기정통부 – 보도자료. 인공지능 데이터 품질 표준안 참고
그림 [2] NIA – AI 학습용 데이터 사업의 실효성 향상을 위한 정책 방향.pdf 참고

이승원
선임 연구원, AI 연구 개발팀
서강대학교, 컴퓨터 공학부 학사
테스트웍스에서 개최한 교육 수료 후, 사회적 가치에 관심을 가지게 되어 테스트웍스에 합류하여 근무 중이다. 기술을 통한 사회적 기여에 관심이 많다.