
들어가며
인공지능 모델은 일상생활에 밀접하게 들어와 있습니다. 우리는 이제 잘 학습된 인공지능 모델을 통한 서비스를 받고 있습니다. 휴대폰으로 신용카드를 인식할 때, 영상을 편집할 때, 필터를 사용할 때 이미지를 처리하는 비전 분야의 딥러닝 모델이 사용됩니다. 자동차에는 어떤 모델이 들어가 있을까요? CCTV에도 인공지능 모델이 들어가 있습니다. ChatGPT를 예로 들어볼까요? 모바일이나 컴퓨터로 웹페이지에 접속하여 ChatGPT의 답변을 받을 수 있습니다. ChatGPT 뒤에는 탄탄한 네트워크로 유저의 질문을 받아, 초거대 언어모델에 입력하고, 모델의 추론 결과를 반환 해주는 ‘컴퓨터들’이 있습니다. 한번에 얼마나 많은 사용자가 접속했을까요? 얼마나 많은 추론을 얼마나 빨리 동시에 할 수 있을까요? 그러려면 어떤 장비가 필요할까요? 컴퓨터, 휴대폰, 자동차, CCTV 같이 다양한 폼팩터에서 인공지능 모델이 어떻게 연산을 할까요?
이 모델들을 학습시키는 데에도 ‘컴퓨터’가 필요합니다. 모델을 추론하는 컴퓨터와 학습을 시키는 컴퓨터는 같을까요? 추론 서비스의 사용량에 따라 다르겠지만, 하나의 모델을 학습시키는 데는 추론을 수행하는 것 보다 훨씬 많은 연산이 오랜 시간 동안 필요합니다. 그래서, 모델을 학습시키는 시스템이 얼마나 안정적이며, 발열과 전력 소비가 적은지도 중요합니다. 하지만, 인공지능 학습 뿐만 아니라 비트 코인 채굴에도 사용되는 GPU가 지구온난화를 가중시키는 원인으로 대두 되고 있습니다. 연산장치의 에너지 효율성은 적은 비용으로 최대의 성과를 내기 위한 것 뿐만 아니라, 세계의 지속 가능한 발전을 위해서도 중요한 문제입니다.
GPU 말고 다른 대안은 없을까요? GPU는 본래 Graphic Processing Unit 입니다. 그래픽을 처리하기 위해서 개발되었고, 우리가 끊김 없이 고사양 게임을 즐길 수 있도록 연산을 제일 잘합니다. 그런데, GPU 보다 더 인공지능을 잘하는 Processing Unit들이 개발되고 있습니다. 예를 들어, TPU(Tensor Processing Unit), NPU(Neural Processing Unit), 또는 FPGA(Field Programmable Gate Array) 같은 것들이 있습니다. 거기다 QPU(Quantum Processing Unit)도 개발 중에 있습니다.
여러분이 인공지능 모델을 사용하는 서비스를 만들기로 한다고 가정해 보겠습니다. 어떤 ‘인프라(Infrastructure)’를 갖춰야 원하는 서비스를 만들 수 있을까요? 새로운 프로세싱 유닛(Processing Unit)들이 실제로 인공지능을 개발하고 서비스하는데 얼마나 효과적일까요? 얼마나 빠르게 얼마나 적은 열을 내면서, 또 얼마나 정확하게 연산을 수행할까요? 어떻게 비교를 해야 인공지능을 잘 한다고 평가할 수 있을까요?
MLPerf 벤치마크
이런 배경으로 등장한 것이 MLPerf(Maching Learning Performance) 벤치마크입니다. 잘 설계된 벤치마크는 타당성과 신뢰성을 갖춘 성능 측정 지표를 도출합니다. 이런 측정 지표가 있어야 더 나은 “ML 시스템”을 위한 업계와 학계의 노력들이 얼마나 효과적이었는지 측정할 수 있고, 경쟁자의 혁신을 “벤치마킹” 할 수도 있습니다. 또 표준화된 벤치마크는 측정 과정을 수월하게 하여 더 빠른 발전을 가능하게 합니다. 거인의 어깨에 선다는 표현이 있습니다. 벤치마크 지표는 내가 서있는 곳이 거인의 발등인지 쇄골인지 어깨인지 알 수 있게 해 줍니다. 내가 거인의 어디쯤 있는지를 얘기할 때 누구는 하늘부터 몇 m 떨어져 있는지를 얘기하고, 누구는 허리부터 몇 인치 떨어져 있는지 얘기하고, 다같이 바닥에서 몇 미터 위에 있는지 알 수 있게 해줍니다.
이처럼 ML 도입 시스템을 평가하기 위한 타당하고 신뢰할 수 있는 벤치마크를 위해 업계와 학계의 연구진과 엔지니어가 모여 만든 것이 “MLPerf” 입니다. 바이두, 구글, 하버드대, 스탠포드대, 캘리포니아 버클리 대학의 연구진과 엔지니어의 미팅을 시작으로, 관련 기업들이 참여하여 “MLCommons”라는 그룹으로 발전하였습니다. AMD, Intell, NVIDIA, arm, Google, Microsoft, Furiosa AI 같은 연산 처리 장치 기업은 물론, TTA(한국정보통신기술협회)와 같은 표준화 기구도 이 조직의 멤버입니다.

이 벤치마크가 성능을 측정하고자 하는 대상인 SUT(System Under Test)는 ML을 학습 또는 추론하는데 필요한 시스템 일체입니다. [그림 1] 이 시스템은 하드웨어와 소프트웨어를 포함합니다.

출처 : “Mlperf inference benchmark, Reddi, Vijay Janapa, et al. ACM/IEEE 2020”
[그림 2]는 MLPerf Inference Benchmark에서 ML 시스템의 단계별 구성 요소를 보여 줍니다. 기업들은 단계별로 호환 가능한 구성 요소를 조합하여 최적의 SUT를 구성합니다. 사실, [그림 2]는 MLPerf Inference Benchmark의 초기 단계(v0.5)에 발표 되었고, 3.0 버전이 공개된 지금 실제 기업들이 구성하는 SUT와는 좀 다릅니다. 실제 기업들의 제출 시스템 스택을 포괄하거나, 구성 요소를 나열하고 있지는 않지만, SUT 및 벤치마크 구성의 복잡도를 가늠해볼 수 있습니다. 이렇게 다르게 구성된 시스템에서도 타당하고 신뢰할 수 있는 “성능 지표의 측정”을 목적으로 하면서, [그림 2]의 상위 3단계(ML Models, ML Data Sets, ML Application)가 “벤치마크 스위트”(Benchmark Suite)에 정의되어 있습니다.
MLPerf Benchmarke의 구성 및 구분
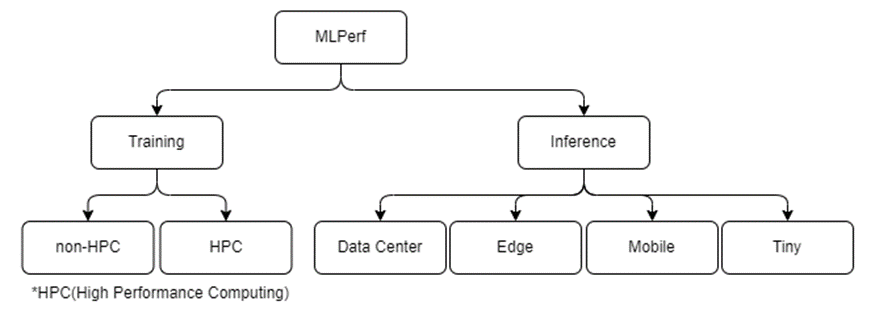
[그림 3] MLPerf는 크게 학습 벤치마크와 추론 벤치마크로 구성되어 있고, 시스템 특성에 따라 Training에 2개의 벤치마크 스위트, Inference에 4개의 벤치마크 스위트로 나뉘어 있습니다.

[그림 4] 벤치마크 스위트는 주요 ML Application에 대한 벤치마크들로 구성되어 있습니다. 각 Application의 대표적인 모델, 데이터 셋, 그리고, 모델의 학습이나 추론 과정을 정의하고 있습니다. 이렇게 정의되어 있는 일련의 규격과 과정이 SUT가 처리해야 하는 부하(“Workload”) 입니다. 각 벤치마크는 모델의 구조나 데이터 전, 후 처리 파이프 라인과 함께, 조정 가능한 하이퍼 파라피터, 학습 프로세스와 같은 세부 사항을 정의하여 규격화 해두었습니다.
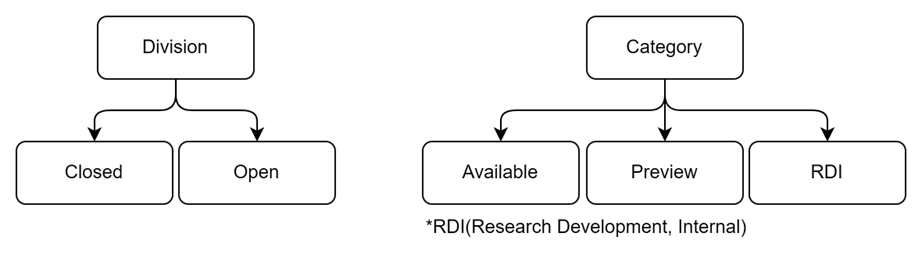
[그림 5] 여기서 벤치마크 규격을 준수하는지에 따라 Closed와 Open 부문으로 구분됩니다. Closed 부문은 모든 규격을 지킨 벤치마크라면, Open 부문은 모든 규격을 지키지는 않은 벤치마크 입니다. Closed 부문의 제출 점수는 서로 비교가 가능하지만, Open 부문의 제출 점수는 비교가 타당하지 않습니다. Open 부문에서는 정해진 규격 외의 pre- 또는 post- processing, 모델의 재학습을 허용하기도 하고, 모델의 구조나 모델의 평가 지표를 바꾸는 것이 가능합니다. Open 부문은 규격화해둔 벤치마크가 ML의 혁신을 방해할 수도 있는 점을 방지하기 위한 부문이라고 합니다.
[그림 6] 제출된 벤치마크 결과는 SUT의 상용화 단계에 따라 3가지의 카테고리로 구분됩니다. SUT의 모든 구성 요소가 구매 가능한 경우 Available, 다음 제출 라운드 때 Available할 수 있는 경우 Preview, 그리고 연구 개발 단계이거나 외부에 제공하지 않는 경우 RDI(Research, Development and Internal)로 나뉩니다.
제출 결과의 해석
자, 그럼 다시 한번 여러분이 인공지능 모델을 사용하는 서비스를 만들기로 한다고 가정해 보겠습니다. 이를 위한 시스템을 갖추고자 합니다. MLPerf benchmark의 제출 본을 어떻게 참고할 수 있을까요? 이를 위해 선택지 테이블을 만들어 보았습니다.
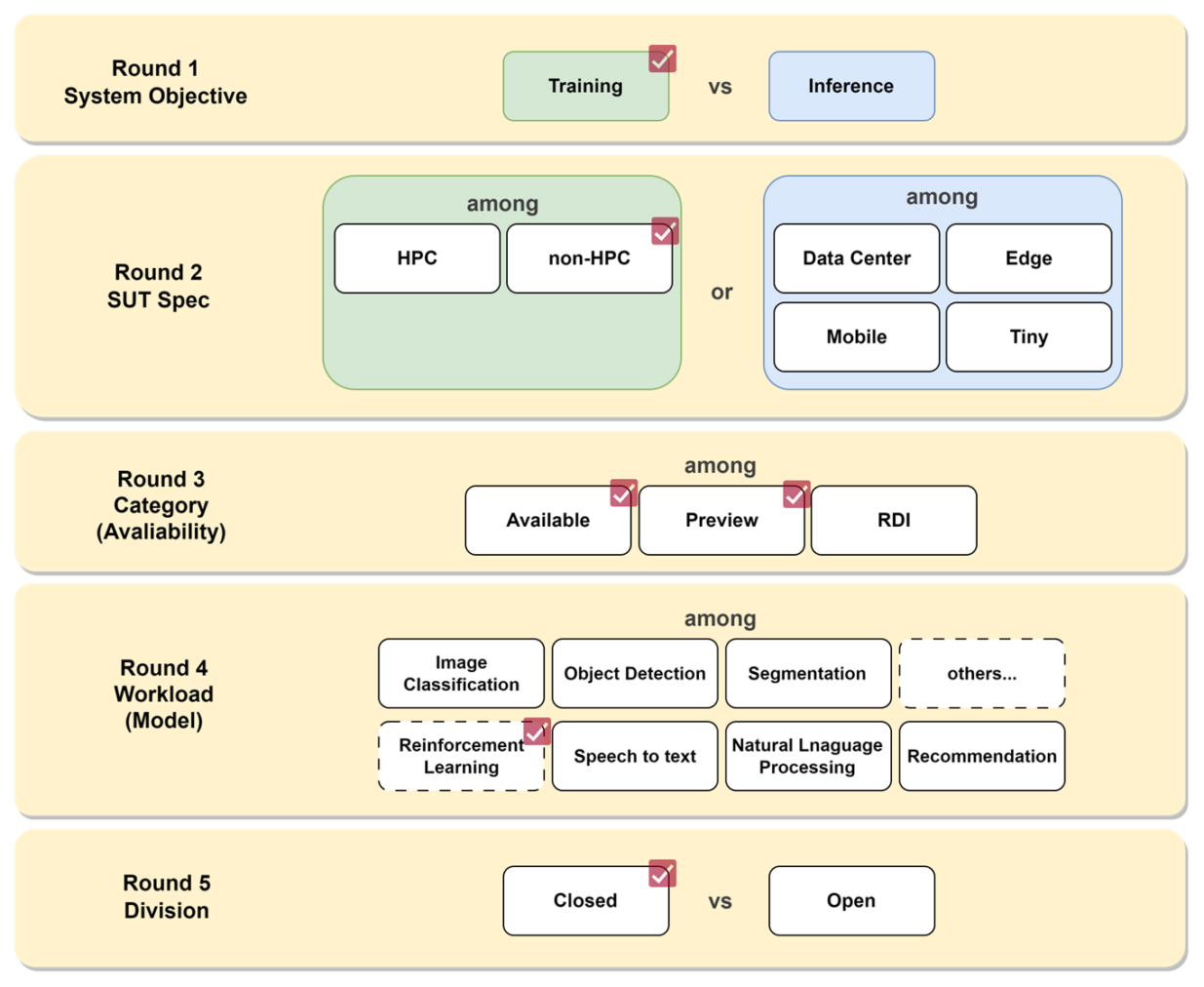
[그림 7] 우선은 모델의 학습이 필요한 상황입니다. 학습을 위한 시스템들의 성능을 한번 알아보겠습니다. 강화 학습을 주력으로 하는 서비스라는 가정 하에 강화학습(Reinforcement Learning)의 벤치마크를 제공하는 non-HPC(High Performance Computing) 벤치마크 스위트를 선택 했습니다. 지금 당장 구매할 수 있는 Available 시스템과 함께, 다음 버전 출시까지 설비 투자를 미루는 게 좋을지 Preview의 제출 결과도 살펴보겠습니다. 점수의 비교가 가능하도록 Closed 부문에서 참조해 보겠습니다. Training 부문은 같은 성능 지표를 달성하기까지 학습에 소요된 시간을 측정합니다. (Time to Train) 강화학습 벤치마크는 Alpha Go 논문을 기반으로 하는 MiniGo 모델을 사용하고, 50%의 승률을 타겟으로 합니다. 가장 빠르게 50% 승률을 달성한 시스템이 좋은 성능을 가졌다고 할 수 있습니다.
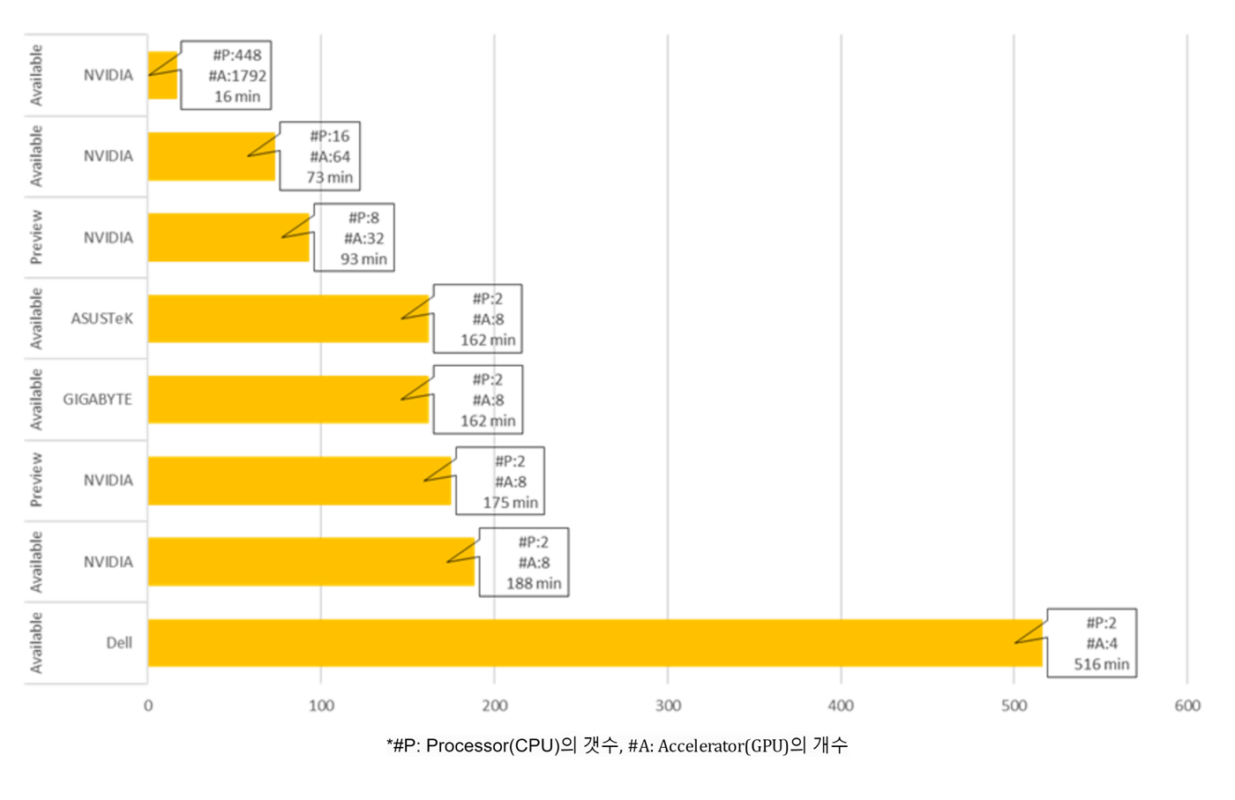
[그림 8]전체 제출결과의 평균은 약 173분 입니다. 가장 적은 시간이 소요된 시스템은 약 16분이 소요된 시스템입니다. 주로 CPU인 프로세서(Processor)가 448개, 주로 GPU인 가속기(Accelerator)의 개수 1,792개가 인상적입니다. 가속기 1,792개가 달린 시스템과 가속기 8개가 달린 시스템은 동등한 비교라고 할 수 없습니다. 그럼 같은 개수로 구성되었다면 더 빨리 학습을 마친 시스템의 가속기나 프로세서가 더 뛰어나다고 해석할 수 있을까요? 모든 조건이 같다면 그렇다고 할 수 있지만, 사실 결과에 영향을 주는 동일하지 않은 다른 요인들이 있습니다. 어떤 ML Framework를 사용했는지, 또 연산 알고리즘을 어떻게 최적화 했는지도 결과에 영향을 줍니다. 동일 개수의 프로세서와 가속기를 가진 시스템도, 다른 종류의 하드웨어 조합, 소프트웨어 스택의 조합으로 구성되어 있기 때문에 벤치마크 성능의 차이를 시스템의 단일 구성 요소로 환원하기는 어렵습니다. 이렇게, ML 시스템의 성능에는 하드웨어의 혁신과 더불어 이를 최대로 활용 할 수 있는 소프트웨어의 최적화까지 종합적으로 영향을 주기 때문에, 벤치마크 지표와 유사한 성능은 전체 SUT가 있어야 기대할 수 있습니다.
마무리하며
MLPerf는 지속적으로 변화 및 발전 중에 있으며, MLPerf Inference 3.0 버전이 올해 4월 발표 되었으며, 이어서 MLPerf Training 의 다음 버전이 공개 예정으로 있습니다.[출처] MLPerf 벤치마크는 ML 시스템에 대한 공신력 있는 성능 지표를 제시해 준다는 점에서 의의가 있습니다. 다양한 어플리케이션의 대표적인 모델을 규격화하고 이에 대한 표준을 정의했다는 점에서 다른 활용도를 찾을 수 있습니다.
References
- Mattson, Peter, et al. “Mlperf training benchmark.” Proceedings of Machine Learning and Systems 2 (2020): 336-349.
- Reddi, Vijay Janapa, et al. “Mlperf inference benchmark.” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020. https://arxiv.org/pdf/1911.02549.pdf
- https://mlcommons.org/en/
- https://github.com/mlcommons
- https://mlcommons.org/en/calendar/

김혜진
연구원, AI 연구 개발팀
경희대학교, 경영학/석사
경희대학교 경영학 MIS 분과에서 데이터 분석 및 머신러닝을 수학하고, 응용 학과인 빅데이터 경영 석사 과정에 진학, NLP(Meaning Representation) 연구 및 프로젝트를 진행함. 과거 웹 플랫폼을 위한 비전 AI 및 OCR web-API 개발 프로젝트를 수행하였고, 테스트웍스의 연구 개발팀에서 정형 데이터 분석, 머신러닝 벤치마크, 비전 AI, 자동화 모델의 연구 및 개발을 진행하고 있다.