
자연어 처리 공부를 하다 보면 반드시 마주치게 되는 단어가 하나 있으니, 바로 Attention입니다. 지금 업계의 최고 수준을 보이는 모델에는 마치 당연한 것처럼 Attention이 포함되어 있습니다. 그렇다 보니 가끔은 Attention 자체에 대해서는 잊어버린 채, 그저 사용하면 좋다더라 하는 정도만 기억하곤 합니다. 가만히 생각해보면 조금 이상하기도 합니다. 문장을 모델에 집어넣어 신경망을 통과시키면 알아서 은닉층들이 문맥 정보를 가져왔지 않았을까 싶습니다. 실상은 그렇지 않았습니다. Attention이 본격적으로 활용되기 전까지 자연어처리 연구자들에게 있어서 모델의 맥락 파악 능력 부족은 큰 골칫거리였습니다. 이번 글에서는 GPT의 뿌리가 된 트랜스포머 구조와 핵심인 Attention에 대해서, 어떤 맥락에서 나타난 것인지 되돌아보도록 하겠습니다.
인공신경망을 사용한 자연어처리의 등장
컴퓨터가 우리의 언어를 직접 이해하도록 하는 자연어 처리 연구는 인공지능 연구가 본격적으로 활성화되기 전부터 이미 시작되었습니다. 이 때에도 문장은 기본적으로 규칙에 따라 나열된 단어들이므로, 특정 단어들이 연이어 나올 확률은 그것이 의미를 가질 때가 훨씬 높을 것이라는 인식은 가지고 있었습니다. 그래서 문장의 일부를 넣었을 때 다음 나올 단어를 예측하는 언어 모델을 만들 때, 코퍼스(말뭉치)를 모은 후 모든 문장을 전부 분석해 그 확률을 계산했습니다. 그래서 이 때의 자연어처리를 ‘통계 기반 자연어처리’ 라고 합니다. 어느정도 성과가 있긴 했지만, 지금에 비하면 썩 좋은 성능을 보이지는 않았습니다. 실제로 입력된 문장들을 바탕으로만 확률을 계산했으므로, 학습 시기에 한 번도 본 적 없는 문장이 나오면 제대로 동작하지 않는 등의 구조적인 한계가 명확했기 때문입니다.
이후 인공신경망이라고 하는, 인공지능의 기반이 되는 구조가 등장했습니다. 인공신경망의 종류도 다양하지만 그 중 자연어처리에 큰 영향을 준 구조는 RNN(Recurrent Neural Network) 입니다. RNN은 입력층과 출력층 사이에 있는 은닉층(Hidden State)이 입력에 따라 계속 변화하는 특성을 가지고 있습니다. 이 은닉층은 입력으로 모델의 실제 입력과 직전 입력에 의해 변화한 은닉층을 받고, 출력을 내보내며 입력값을 바탕으로 은닉층 내부가 변합니다. 은닉층이 계속해서 자기 자신을 참조하기 때문에 순환(Recurrent)이라는 이름이 붙었습니다. 일반적인 인공신경망이 학습을 통해 내부의 파라미터를 확정짓는다면, RNN은 내부 신경망이 어떻게 변화할지에 대한 정책을 학습합니다.

RNN 구조의 가장 큰 장점은 입력과 출력의 길이를 자유롭게 설정할 수 있다는 점입니다. 왜냐하면 고정된 길이가 아닌 유동적인 시계열 데이터를 처리할 수 있게 되기 때문입니다. 문장마다 길이가 다른 자연어처리에 안성맞춤이죠. 예를 들어 입력받은 문장을 어떤 기준에 맞게 분류하려고 한다면, 문장의 단어를 순서대로 하나씩 받은 후, 첫 출력값을 이용해 판별하는 식입니다. 문장을 다른 언어로 번역한다고 하면, 입력 단어를 순서대로 받고, 사전에 정의된 문장 종료 기호가 최종적으로 입력되면 그때부터 출력을 순차적으로 시작합니다. 여기서 출력을 사용하지 않는, 단어를 입력받고 은닉층이 변화하는 구간을 인코더(Encoder), 출력값을 사용하는 구간을 디코더(Decoder) 라고 부릅니다. 인코더[1]에서 디코더[2]로 넘어갈 때 전달되는 것이 입력된 문장에 의해 변화된 은닉층 그 자체이니, 그야말로 원리를 함축한 적절한 명칭이라고 할 수 있겠습니다.
[1] 인코더: 입력 신호를 다음 처리 단계에 알맞도록 부호화하는 장치. (출처: 고려대한국어대사전) [2] 디코더: 입력된 부호에 대응하는 출력을 발생시키는 전자 회로. [유의어] 해독기 (출처: 고려대한국어대사전)
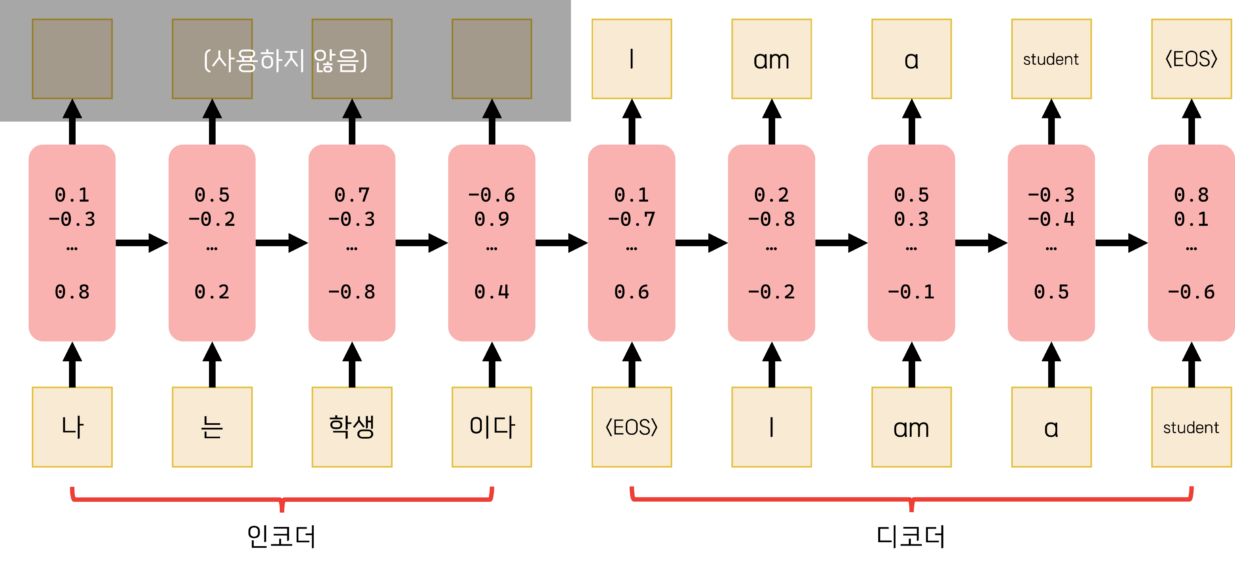
그런데 여기서 문제가 하나 발생합니다. 입력 문장의 길이가 길어질 때, 입력된 내용을 디코더가 온전하게 기억하지 못하는 현상이 발견된 것입니다. 특히 문장 전체를 이해해야 하는 질의응답(QnA)이나 번역에서 그 문제가 크게 두드러졌습니다. 훈련 단계에서 모델은 일단 예측해본 출력값과 실제 답 간의 오차를 역전파하여 내부 파라미터를 조절하는 식으로 학습하는데, 최종 출력 지점과 초반 입력 지점 사이의 거리가 너무 멀면 그 오차가 제대로 전달되지 않았던 것입니다. 이를 Vanishing Gradient Problem이라 합니다.
이 문제를 해결하기 위해 연구자들은 LSTM(Long Short-Term Memory)라는 구조를 만들어냈습니다. 은닉층이 정보를 오래 유지할 수 있도록 기존 RNN의 은닉층 안에 추가적인 구조를 삽입하여, 거리가 멀더라도 그래디언트 역전파가 잘 일어나도록 했습니다. 한걸음 더 나가서 BiLSTM(Bidirectional LSTM) 이라는 LSTM을 응용한 모델도 만들어졌습니다. 서로 반대 방향의 LSTM을 평행하게 두어, 은닉층이 전방향과 역방향의 맥락을 모두 파악할 수 있게 하는 것입니다. LSTM과 BiLSTM 구조가 도입되면서 인공지능 기반 자연어처리의 정확도가 크게 올랐습니다.
Attention의 등장
이 때쯤부터 인공지능을 연구한 논문에 나타나기 시작하는 단어가 있었으니, 바로 Attention입니다(트랜스포머 구조에서 지겹도록 들으신 그 Attention이 맞습니다). LSTM으로도 원하는 만큼의 성능이 나오지 않아 그 이유를 찾아보니, 여러 입력들을 거쳐서 바뀐 은닉층의 최종 상태만 디코더로 넘겨주는 것이 한계의 원인으로 지목된 것입니다. 그래서 지금까지 인코더에 입력되면서 변화한 은닉층의 모든 상태를 다 전달해주는 구조가 제안되었는데, 그것이 바로 Attention입니다. 기계 번역의 품질을 높이려는 한 연구에서는, BiLSTM을 인코더로만 사용하고, 완전히 분리된 별도의 디코더를 하나 따로 두었습니다. 그리고 인코더에서 디코더로 값을 전달할 때, 은닉층이 거쳐온 상태를 모두 참조하여 만들어진 벡터를 전달했습니다. 그러면 이 모델은 학습 과정에서 출력 때 어디를 더 집중해서 봐야 하는지 이 벡터를 이용해 알 수 있게 됩니다. 이 ‘집중’ 하는 구간을 시각화 시켜보면 번역할 때 어순이 바뀌는 표현이 있을 때 이 부분만 순서를 바꾸어서 ‘집중’하고 있는 것을 볼 수 있습니다. 덕분에 성능이 크게 뛰어, 당시 다른 모델들에 비해 BLEU(기계번역의 품질을 평가하는 지표) 점수도 10%p 가까이 높은 성능을 보였다고 합니다.

Bahdanau, Dzmitry & Cho, Kyunghyun & Bengio, Y.. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. ArXiv. 1409.
트랜스포머 구조도 크게 보면 인코더와 디코더로 나뉘어 있습니다. 앞서 살펴본 모델에서의 인코더 디코더와 개념은 동일합니다. 그런데 트랜스포머 구조를 자세히 보면 단순히 인코더와 디코더 사이에만 Attention이 전달되는 것이 아니라, 인코더와 디코더 각 층 안에도 Attention이 적용되어 있습니다. 이렇게 Attention을 전달하는 대상이 디코더가 아니라 자기 자신인 구조가 Self-Attention입니다. 트랜스포머 구조와 Attention, Self-Attention에 관해서는 테스트웍스 블로그의 이전 글에 자세하게 설명되어 있습니다.
트랜스포머를 반으로 가르다
여기서 새로운 시도를 하는 연구자들이 등장했습니다. 인코더와 디코더를 같이 쓰는게 아니라, 어느 한쪽만 따로 떼어내어 학습을 시켜본 겁니다. 인코더만 사용하는 BERT(Bidrectional Encoder Representations from Transformers)를 개발한 연구자들은 인코더를 모두 통과한 후 디코더로 전달되는 부분에 문장의 중요 내용이 함축되어있다는 점에 초점을 맞췄습니다. 인코더를 통과하고 나면 각 단어별로 모델이 학습한 의미를 담은 벡터가 출력되므로, 각 벡터들을 단어 임베딩[3]이라고 볼 수도 있는 겁니다. 더군다나 이 벡터들은 단어 하나만을 본 것이 아니라 Self-Attention을 통해 주변 단어들과의 관계를 학습한, 즉 문맥을 파악한 임베딩입니다. BERT의 개발자들은 인코더만 사용하는 대신, 인코더의 레이어 개수를 기존 트랜스포머의 6개에서 12개(BERTBASE)나 24개(BERTLARGE)로 늘렸습니다. 이제 이 BERT를 이용해 문장 중간중간 고의로 낸 빈 칸을 추론하도록 pre-training을 한 것을 언어 모델이라고 합니다. 그리고 다른 자연어 처리 과제에서 사용할 땐 실제로 실행할 과제(분류, 요약, 등)에 따라 추가적인 레이어를 놓고, 새 레이어를 위주로 미세하게 학습하는 fine-tuning을 해 주는 식으로 활용합니다. 이렇게 fine-tuning된 모델은 당시의 다른 모델들보다 거의 모든 면에서 높은 성능 수치를 보였습니다.
[3] 혹시 예전에 단어 임베딩을 배우시면서 임베드 벡터를 더하고 빼는 것으로 우리가 알고 있는 상식이 표현된다는 이야기를 들어보신 적이 있나요?
(King – Man + Woman = Queen) 그건 BERT 이전의 고정된 형태의 단어 임베딩에 관한 이야기입니다. BERT를 통해 출력된 벡터들은 문맥을 함께 고려하기 때문에 같은 단어라고 하더라도 임베딩이 달라질 수 있습니다.
디코더만 사용한 연구자들도 있었습니다. 바로 GPT(Generative Pretrained Transformer)입니다. (네, 여러분들이 아시는 chatGPT의 원형이 되는 모델입니다.) 사실 GPT는 BERT보다 먼저 만들어진 모델입니다. 눈치가 빠르신 분은 여기서 이런 질문을 하실 겁니다: ‘인코딩이 되지 않았는데 어떻게 디코딩을 하지?’ 이는 인코더와 디코더의 기본적인 형태가 크게 다르지 않기 때문에 가능했습니다. 차이점은 크게 두 가지가 있습니다. 인코더와 같이 있을 때의 디코더는 매 레이어마다 인코더의 정보를 한 번씩 참조합니다. GPT에서는 인코더가 없으므로 인코더의 정보를 참조하는 부분이 없습니다. 또한, 인코더는 전체 문장을 한꺼번에 입력받아 문장 전체에서 문맥 정보를 찾아내지만, 디코더는 생성해내는 쪽에 중점을 두고 있기 때문에 문장 전체가 아니라 지금까지 생성된 부분까지만 참조할 수 있습니다. 인코더는 이미 인쇄된 책에서 문장 앞뒤를 왔다갔다 하며 정보를 긁어오는 독해 문제를 푼다면, 디코더는 지금까지 들은 부분에서 정보를 축적해가며 이해하고 예측하는 청해 문제를 푼다고 비유해볼 수 있겠습니다. 그런데 이것도 어디까지나 정보의 일부가 가려졌을 뿐이지 근본적인 구조가 바뀌진 않았으므로 인코더와 마찬가지로 디코더의 첫 입력 부분에 단어를 넣는 것이 가능합니다.
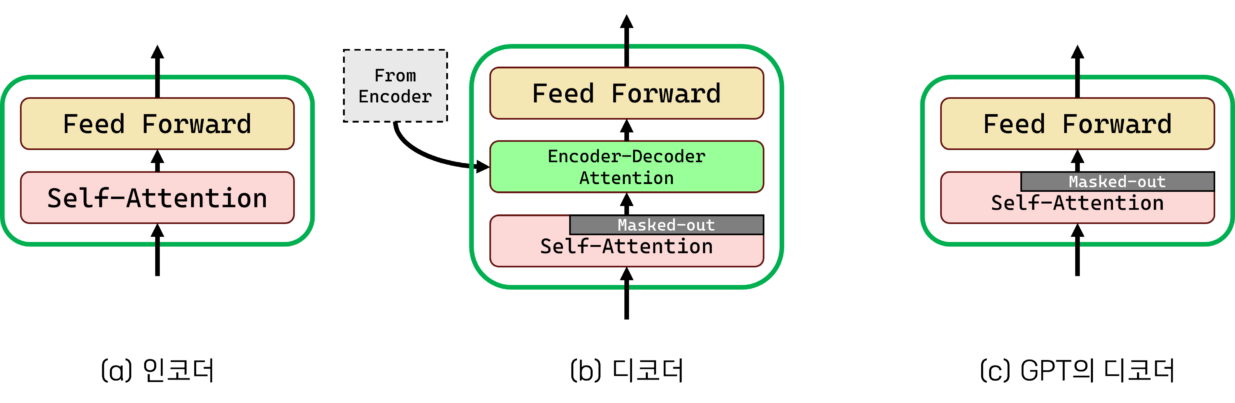
그렇기 때문에 다른 조건이 동일하다면, GPT는 BERT에 비해 파악할 수 있는 문맥의 범위가 좁습니다. 실제로 BERT 구조를 제시한 논문에서 GPT는 이와 같은 문제가 있어 질문에 대한 대답을 하는 Question Answering에 취약하다고 꼬집었고, 실제로 실험에서도 BERT가 GPT보다 성능이 우수했습니다.
그런데 몇 년이 지난 지금, GPT는 세간에 이름을 떨치며 엄청난 활약을 펼치고 있고, BERT는 이 Transformers 구조를 이용한 대표적인 모델로 과거의 영광을 안고 뒤로 물러나고 있습니다. 어떻게 된 일일까요? 다음 포스트에서 살펴보겠습니다.

한승규
연구원, AI 연구 개발팀
고려대학교, 컴퓨터학과 석사
고려대학교 자연어처리 및 인공지능 연구실에서 자연어처리 관련 연구를 하였으며, 다양한 데이터 셋으로 모델을 파인튜닝하는 프로젝트들을 진행했다. 현재는 테스트웍스 AI본부에서 LLM과 multi-modal 관련 연구를 진행하고 있다.