
인공지능(AI)과 머신러닝(ML) 기술의 발전은 우리 생활 곳곳에서 큰 변화를 이끌어내고 있습니다. 이러한 기술을 효과적으로 구현하기 위해서는 대규모의 데이터가 필요합니다. 그러나, 수집된 모든 데이터에 대하여 사람이 일일이 라벨링 하는 것은 막대한 시간과 비용을 요구하는 작업입니다. 따라서 데이터 라벨링 작업의 효율성을 높이는 방법이 중요한 과제로 떠오르고 있습니다. 이러한 문제를 해결하기 위한 접근법 중 하나가 바로 “Active Learning”입니다.
Active Learning이란?
Active Learning은 모델이 학습 과정에서 유의미한 데이터를 선택하여 학습하는 방법입니다. 즉, 모델이 현재 상태에서 자신에게 가장 학습에 도움이 될 것 같은 데이터를 선택하여 사람에게 라벨을 붙이도록 요청합니다. 이를 통해 적은 양의 데이터로도 높은 성능을 가진 모델을 구축할 수 있습니다.
Active Learning의 과정은 여러 단계로 나누어 분석하면, 아래와 같이 정리할 수 있습니다.
1. Select from unlabeled pool: 기존 모델의 학습 결과를 바탕으로 라벨링이 되지 않은 데이터셋으로부터 라벨링을 부여할 데이터를 선별합니다. 이전에 학습된 모델이 없다면, 개발자가 임의로 라벨링을 진행할 초기 데이터셋을 결정합니다.
2. Annotate data: 쿼리에 대하여 사람이 라벨링을 진행합니다.
3. Update labeled pool: 라벨링이 완료된 데이터를 기존 labeled pool에 포함시키고, 이를 학습용 데이터셋으로 사용합니다.
4. Train model: 학습용 데이터셋을 이용하여 모델 학습을 진행합니다.
1~4번의 과정을 cycle이라고 일컬으며, 유의미한 성능에 도달하거나 사용 가능한 리소스가 제한될 때까지 위의 cycle을 반복하여 수행함으로써 라벨링 한 데이터를 확보합니다. 이러한 방식으로 학습을 진행하면 전체 데이터셋 대비 일부분을 사용하여 학습을 진행하므로 목표한 결과에 도달하기까지의 리소스를 줄일 수 있습니다. 전체 파이프라인은 아래의 그림을 참조 바랍니다.
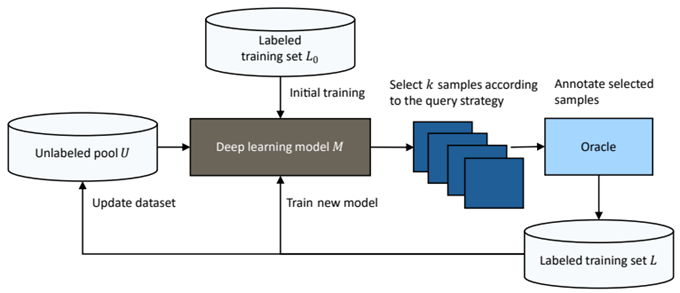
출처: L. Eversberg and J. Lambrecht, “Combining Synthetic Images and Deep Active Learning: Data-Efficient Training of an Industrial Object Detection Model,” Journal of imaging, vol. 10, no. 1, pp. 16–16, Jan. 2024, doi: https://doi.org/10.3390/jimaging10010016.
대표적인 쿼리 전략
Active learning의 cycle 중 첫 번째 단계에서 라벨링을 부여할 데이터를 선별해야 하는데, 이때 ‘쿼리’라는 개념이 등장합니다. Query(쿼리)는 라벨링을 진행할 데이터를 선별하는 과정을 의미하고, 선별 과정의 여러 전략들을 쿼리 전략(query strategy)이라고 합니다. Active learning에서 주로 사용되는 쿼리 전략은 Uncertainty Sampling, Query By Committee, Expected Model Change 등이 있습니다. 이러한 전략 모두 이전 cycle의 산출물(데이터셋 혹은 모델 학습 결과)을 활용하여 현재 cycle을 진행한다는 공통점을 갖고 있습니다.
1. Uncertainty Sampling: 모델이 데이터를 분류할 때, 확신이 적은 데이터를 샘플링하는 방식입니다. 확신이 적다는 것은 어떤 클래스로 분류해야 할지 모델에게 혼동을 일으키는 데이터를 의미합니다. 모델의 입장에서 분류하기 어려운 데이터를 제대로 처리할 수 있다면, 분류하기 쉬운 데이터도 당연히 처리할 수 있으므로 불확실성이 높은 데이터를 선택해야 합니다. 불확실성을 이용하는 것은 학습에 단순하고 가장 직관적인 방법이며 이를 측정하는 지표는 top confidence와 maximum entropy 방식이 있습니다.
- Top confidence: 모델이 예측한 클래스 확률 값을 사용하는 방법입니다. 모델의 클래스 예측 값으로 구성된 집합에서 확률이 낮을 수록 예측하기 어렵고 확신하지 못하는 데이터임을 의미합니다.
- Maximum entropy: 엔트로피를 이용한 방법입니다. 엔트로피 값이 높은 데이터는 모델이 예측할 때 확신이 낮은 데이터임을 의미합니다.
따라서 uncertainty sampling은 top confidence 기준 낮은 값을 maximum entropy 기준 높은 값을 갖는 데이터를 라벨링하는 전략입니다.
2. Query By Committee: QBC는 앙상블을 이용한 쿼리 전략으로, 확신이 적은 데이터를 샘플링한다는 특징이 uncertainty sampling과 동일합니다. 이를 앙상블 관점에서 해석하면, 여러 모델을 사용하여 예측할 때 모든 모델이 동일한 결과로 예측하는 것보다는 서로 다른 예측 결과를 보여주는 데이터가 불확실성이 높은 데이터를 의미합니다. 따라서 결과가 가장 상충하 데이터를 선택하는 방식이고 vote entropy 지표를 주로 사용합니다.
- Vote entropy: 앙상블을 이용한 예측에서 엔트로피를 적용한 방법입니다. 엔트로피 값이 높은 데이터는 여러 모델이 예측할 때, 예측 결과가 통일되지 않고 상이함을 의미합니다.
3. Expected Model Change: 앞서 두 방식은 불확실성을 기반으로 데이터를 선택하여 모델이 예측하기 모호하다고 추정되는 데이터를 라벨링 하도록 유도하지만, EMC는 불확실성이 아닌 모델의 변화량에 집중합니다. 모델이 새로운 라벨로 인해 얼마나 변화할지를 예측하고, 이 변화를 최대로 이끌어내는 데이터를 선택합니다. 변화량이라는 키워드를 반영하기 위해 expected gradient length 지표를 주로 사용합니다.
- Expected gradient length: 모델이 갖고있는 파라미터의 기울기 변화량을 비교한 방법입니다. 특정 데이터가 학습 데이터셋에 포함되었을 때, 모델의 가중치가 얼마나 변하는지를 의미합니다.
EMC는 학습이 진행될 때 모델의 변화량에 가장 큰 변화를 줄 수 있는 데이터를 고르는 것이지만, 모델의 학습 방향은 고려하지 않으므로 잘못된 방향으로 가중치가 업데이트될 수 있다는 문제점을 갖고 있습니다. 따라서, 적절한 파라미터 튜닝이 동반되어야 합니다.
기대효과
Active learning의 가장 큰 장점은 효율적으로 데이터를 활용하여 학습을 진행할 수 있다는 것입니다. 중요한 데이터만 선택하여 학습하여 전체 데이터에 비해 적은 양의 데이터로도 높은 성능을 달성할 수 있습니다. 이 과정에서 매 cycle마다 모델을 분석할 수 있으므로 빠르게 피드백을 진행할 수 있습니다. 또한, 학습에 필요한 리소스를 절약할 수 있습니다. 모든 데이터를 라벨링 하지 않고 학습에 유의미한 데이터만 라벨링을 진행하므로 학습에 필요한 시간과 비용을 절약할 수 있습니다.
응용 분야
학습에 유의미한 데이터를 우선적으로 선별하는 방법은 자연어처리 혹은 비전을 가리지 않고 다양한 도메인에서 활용될 수 있습니다. 텍스트 데이터의 분석에서 중요한 문장이나 단어를 선택하여 라벨링 함으로써 학습에 필요한 문장을 줄여 번역, 감성 분석 등의 성능을 개선할 수 있습니다. 또한, 자율 주행 환경을 인식할 때 시각적 정보를 많이 포함한 중요한 도로 상황이나 객체를 우선적으로 학습하여 모델의 객체 인식 능력을 빠르게 향상시킬 수 있습니다.
테스트웍스에서는 active learning 도입을 고려하여 PoC에 착수했습니다. 도로 주행 영상을 학습하여 객체 탐지를 진행하는 작업에서 학습에 도움이 되는 데이터셋 제작을 목표로 했고, 푸리에 변환과 데이터의 손실 값을 예측하는 방식을 이용하여 모델 학습에서의 효용성을 판단했습니다. 아래의 이미지는 데이터의 손실 값 기준으로 정렬한 결과입니다. 왼쪽의 손실 값이 큰 이미지는 복잡하고 객체를 많이 포함하고, 반면 오른쪽의 손실 값이 낮은 이미지는 단조로운 도로 장면을 확인할 수 있습니다.

푸리에 변환과 손실 값을 이용하여 데이터셋을 구축한 결과, 무작위로 데이터셋을 생성할 때보다 더 많은 객체를 확보하여 active learning을 두 단계로 자사 제품인 blackolive에 탑재할 예정입니다. 우선 작업물의 상대적인 난이도를 측정하는 시스템의 도입이며, 이는 사용자의 프로젝트 관리에 도움이 되는 기능입니다. 이후 프로젝트의 효율적인 진행을 위해 난이도가 낮은 작업물에 한하여 auto-labeling을 지원할 예정입니다.
마무리
Active Learning은 인공지능 모델 학습의 효율성을 높이고, 적은 양의 데이터로도 유의미한 성능에 도달하도록 학습하는 혁신적인 방법입니다. 수많은 데이터 중 필요한 데이터만 선별하여 비용 및 시간 절감 효과를 제공하기 위해 self-supervised learning의 pretext task를 적용하는 등 여러 연구가 진행 중입니다. 다양한 연구 동향이 존재하는 만큼, 앞으로도 여러 분야에서 Active Learning의 활용이 더욱 활발해질 것으로 기대됩니다.

이준서
연구원, AI 연구 개발팀
아주대학교 소프트웨어학과 학사
아주대학교 Computational Intelligence Lab에서 딥러닝 기반 컴퓨터 비전을 연구했다. 현재 테스트웍스 AI 연구 개발팀에서 active learning에 관한 연구를 진행한 바 있다.