
지난 글에서는 별도로 사람의 개입 없이 자동으로 채점 할 수 있는 기계적 평가 법에 대해 알아보았습니다. 하지만 동시에 그 기계적 평가에 의한 점수가 높다고 항상 사람이 좋은 문장으로 평가할만한 문장이 아니라는 것도 알아보았습니다. 그래서 이번에는 사람의 손을 완전히 떠난 평가가 아니라, 사람의 손길이 닿아있는 평가 방법에 대해 알아보려고 합니다.
[벤치마크를 이용한 평가]
벤치라크는 말을 들어본 적이 있으신가요? 벤치마크란 보통 컴퓨터나 스마트폰에서 해당 기기의 성능을 측정하기 위해 일부러 부하를 주는 것을 말합니다. 그래픽카드 성능을 테스트하는 벤치마크 프로그램이라면 화려한 효과가 많고 넓은 필드의 3D 그래픽을 표시시키고, 초당 프레임 수를 얼마나 높이 유지할 수 있는 가를 테스트하는 것입니다. 비슷하게 LLM에서도 벤치마크 형식으로 평가할 수 있습니다.
바로, LLM이 실제로 적용될법한 분야에 관해 다양한 문제들을 준비하고, 모델이 이에 어떻게 답변하는지를 평가하는 것입니다. 이렇게 되면 모델의 순수한 성능보다는 어느정도 목적에 맞게 fine-tuned된 후의 성능을 측정하게 됩니다.
이런 벤치마크용 데이터셋의 특징은 학습용 데이터셋과 평가용 데이터셋이 확실하게 분리되어 있고, 어떤 경우에는 평가용 데이터셋을 아예 비공개처리하기도 한다는 점입니다. 즉, 같은 데이터로 학습한 뒤 같은 문제로 평가하여 모델의 성능을 공정하게 평가하겠다는 것입니다.
또 하나의 특징은 평가를 객관적으로 하기 위해 모델이 답하는 방법을 대부분 객관식 형태로 제한했다는 점입니다. 문장을 생성해야 하는 형태의 문제도 직접 모델이 문장을 생성하는 것이 아니라, 주어진 문장들 중에서 가장 적절한 것을 모델이 숫자로 선택하게 하는 것입니다.

국제적인 논문지에서 주로 사용되는 영문 벤치마크 데이터로는 GLUE, MMLU, BIG-Bench 등이 있습니다.
GLUE(General Language Understanding Evaluation) 데이터셋은 주로 자연어로 된 텍스트를 이해하는 태스크를 모아놓은 벤치마크입니다. 문장의 맞춤법이 맞는지 검사하거나, 두 문장의 유사도를 평가하거나 하는 등의 태스크가 그 예입니다. GLUE 데이터셋에서 모델의 성능이 왠만한 사람의 수준까지 이르르자 이후 같은 형식이지만 더 긴 지문으로 구성되어 더 깊은 사고능력을 요구하는 SuperGLUE 데이터셋이 만들어지기도 했습니다.
MMLU(Massive Multitask Language Understanding) 또한 대표적인 벤치마크 데이터셋 중 하나입니다. MMLU는 모델이 사전학습동안 내재한 지식을 평가하려는 목적을 가지고 개발되었습니다. 인문학, 사회과학, 미시경제학 등 다양한 분야의 질문들이 모여 있습니다. 모델은 질문이나 지문을 읽고, 4개의 선택지 중 가장 적합한 것을 하나 골라야 합니다.
벤치마크를 이용해 모델을 평가하려는 시도는 여기서 멈추지 않고, 분야를 더 넓혀갔습니다. 구글에서 주관하여 구축한 BIG(Beyond the Imitation Game)-Bench는 200개가 넘는 유형의 문제들로 구성된 벤치마크 데이터셋입니다. 이중에서 평균적인 사람의 점수를 앚기 넘지 못한 23개정도의 유형을 따로 묶어 BBH(Big-Bench-Hard)라고 부르기도 합니다.
모델의 한국어 능력을 영어로 평가할 수는 없는 노릇이기 때문에, 한국어로 만들어진 데이터셋도 많이 개발되었습니다.
KLUE는 GLUE와 같은 형태로 제작된 한국어 데이터셋으로, GLUE를 단순히 번역한게 아니라 아예 한국어의 특징을 살려 새로 구축했다는 특징이 있습니다. 개체명 인식이나 주제 분류, 기계독해 등을 포함한 총 8가지 영역에서 모델을 평가합니다.
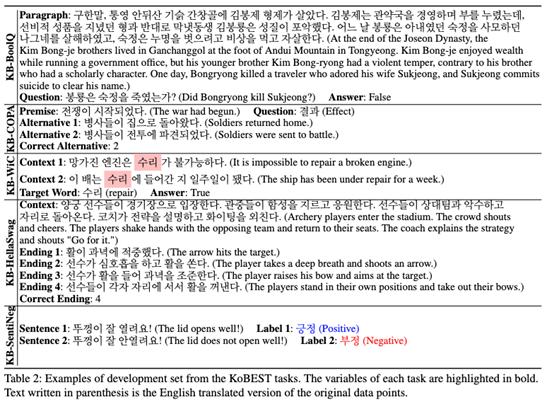
KoBEST 데이터셋 역시 영어로만 존재하던 벤치마크 데이터셋을 한국어로 재구축한 벤치마크입니다. 특히 두 문장에 공통적으로 사용된 단어가 같은 뜻인지 동음이의어인지 구분하는 문제나, 주어진 상황 이후에 가장 일어날법한 상황을 골라내는 문제가 특징적입니다.
In Proceedings of the 29th International Conference on Computational Linguistics (pp. 3697-3708).
단순한 평가를 넘어 공개적으로 리더보드를 열어 경쟁을 유도하는 경우도 있습니다. AIhub 홈페이지에 공개되어 있는 Open Ko-LLM Leaderboard ( https://www.aihub.or.kr/leaderboard/view.do )가 대표적인 예입니다. 여기서는 모델을 총 다섯가지 분야(추론능력, 상식능력, 언어이해력, 환각방지능력, 한국어 상식생성능력)에 대해서 평가하고, 그 성적을 순위표에 기록합니다.
[사람에 의한 평가]
지금까지 다양한 모델 성능 평가용 벤치마크 데이터셋에 대해 알아보았습니다. 기계적 평가법에서부터 벤치마크 평가법까지 알아보신 여러분은 어쩌면 이렇게 생각하실지도 모릅니다. ‘여기서 잘 한다고 우리가 실제로 쓸 서비스에서도 잘 동작한다고 장담할 수 있을까?’ 그런데 안타깝게도 LLM을 이용하여 만들 수 있는 서비스는 무궁무진하기 때문에 어떻게 해도 일반화된 평가 기준을 마련할 수 없는 것이 현실입니다. 그래서 그때그때 기준을 매번 세우고 이걸 이용해서 평가할 수밖에 없습니다. 마지막으로 이렇게 실제 서비스 수준에서 평가하는 방법과, 그 방법을 마련하는 기준에 대해 짚고 넘어가려고 합니다.
먼저, 위에서 지금까지 언급했던 기본적인 언어 능력을 봅니다. 벤치마크 평가에서는 실제로 모델이 생성하지 않기도 했고, 기계적인 평가는 그 점수가 높다고 항상 사람이 보기에 만족스럽지는 않을 수 있다는 문제점이 있었습니다. 그래서 공통적으로 생성된 문장의 언어적 능력을 평가하는 지표로 정확성, 유창성, 일관성을 사용합니다. 정확성 평가란 우리가 모델에 지시한 내용이 정확하게 수행되었는지, 질문을 한 경우 대답에 거짓이 있지는 않은지 확인하는 것입니다. 유창성 평가에서는 생성된 문장에 문법적인 오류는 없는지, 어색한 표현은 없는지를 확인합니다(평가 설계에 따라 문법적인 오류는 따로 별도의 지표로 분리되는 경우도 있습니다). 일관성 평가에서는 생성된 답변에 자기모순적인 내용은 없는지, 혹은 말투가 비슷하게 유지되는지 등을 평가합니다.
다음으로, 모델이 사용될 시스템의 요구사항을 정확히 수행하는지에 대한 평가를 합니다. 예를 들어 STT(Speech-To-Text)를 이용하여 회의 요약을 자동으로 생성해주는 시스템을 평가한다고 합시다. 성능이 우수하다면 회의록의 형식(날짜, 주제, 참석자 등)을 잘 지키고, 주요 키워드를 적절하게 추출하며, 발언자를 잘 구분되어있어야 합니다. 이렇게 이상적인 상황을 세워두고, 각각의 요소에 대해 얼마나 잘 수행했는지를 평가하는 것입니다.
평가 기준부터 실제 평가까지 모두 사람이 하기 때문에, 각각에 대해 신중을 기해야 합니다. 예를 들어, 평가 기준을 세울 때는 더 중요한 요소에 따라 점수에 가중치를 부여하는 것도 고려해보아야 합니다. 언어적 능력을 평가하는 경우 관련 분야의 전문가(관련 학과의 특정 학위 이상 소지자)로 구성하거나, 실제 서비스를 이용할법한 사람을 대상으로 할 필요가 있습니다.
여기까지 LLM을 평가할 수 있는 다양한 방법에 대해 알아보았습니다. 자동화를 할 수 있는지, 공정성을 중요시 여기는지, 실제 서비스의 관점에서 보는지에 따라 각각 최선의 평가법이 달라진다는 것을 보셨습니다.

한승규
연구원, AI 연구 개발팀
고려대학교, 컴퓨터학과 석사
고려대학교 자연어처리 및 인공지능 연구실에서 자연어처리 관련 연구를 하였으며, 다양한 데이터 셋으로 모델을 파인튜닝하는 프로젝트들을 진행했다. 현재는 테스트웍스 AI 본부에서 LLM과 Multi-modal 관련 연구를 진행하고 있다.