
유튜브, 넷플릭스, 틱톡 등 동영상을 활용한 서비스들이 지속적으로 인기를 끌고 있습니다. 이러한 인기에 힘입어, 동영상을 활용한 많은 인공지능 연구들도 꾸준히 발전되고 있는데요. 동영상을 이용한 많은 연구가 존재하지만, 이번 글에서는 동영상을 입력으로 하여 입력된 동영상과 유사한 동영상들을 찾아내는 “영상을 이용한 영상 검색(이하 video retrieval)”에 대해 다뤄보려고 합니다.
검색(Retrieval)이란?
검색은 입력된 쿼리를 기반으로 데이터베이스에 존재하는 데이터들을 유사한 순서대로 정렬하는 문제입니다. 특정 물체가 어떤 물체인지를 찾아주는 문제가 분류(Classification)라고 한다면, 검색의 경우에는 데이터베이스에 저장되어 있는 유사한 물체들을 반환하는 문제라고 볼 수 있습니다.
동영상이란?
동영상이 어떤 특징을 가지고 있길래, 동영상으로 검색을 하려는 걸까요? 가장 큰 특징은 다수의 프레임(이미지)으로 구성되어 연속적이라는 점입니다. 그럼 이 특징이 이미지에 대비해 어떤 차이를 만들까요? 우선 더 많은 이미지가 존재하기 때문에, 당연히 더 많은 정보량을 가지게 됩니다. 하지만 가장 큰 차이는 시간(Temporal) 축에 따른 정보 차이가 있습니다. 걷는 사람과 뛰는 사람을 구분해야 한다고 생각해봅시다. 어떤 부분에서 차이가 있을까요? 정답은 속도입니다. 이미지에서는 속도를 담을 수 없기 때문에, 비디오의 시간 축 정보가 이미지와 비교했을 때 하나의 큰 장점이 될 수 있습니다.
시간 축이 있는 비디오는 이미지와는 큰 차이가 또 존재합니다. 드라마나 영화 같은 동영상을 머릿속에 떠올려보면, 장면이 휙휙 바뀌는 것을 떠올리실 수 있을 겁니다. 이런 드라마나 영화에서는 등장인물이 화면에 나왔다가, 풍경이 나오기도 하는 등의 시각적으로 다양한 장면들이 등장하는데요. 이때, 시각적으로 유사한 프레임들을 묶어 샷(Shot)으로 분류하고, 이 시각적으로 유사한 샷을 묶어 의미론적으로 같은 주제를 다루는 씬(Scene)으로 분류합니다.
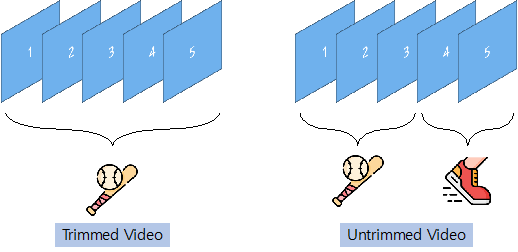
이미지 연구에서도 물체가 잘 드러날수록 분류 난이도가 쉬워지는데요. 앞서 언급했듯이 비디오는 다수의 프레임으로 구성되어 있기 때문에, 프레임안에 특정 주제가 잘 드러나면서도 연속적인 프레임 내에서도 이 주제가 잘 드러나야 합니다. 즉, 시간 축에 따라 어떤 정보가 주어지는지에 따라 모델이 풀 문제의 난이도를 결정하는 것이죠. 따라서 연구의 편의상 주제가 1개면 trimmed video, 주제가 2개 이상이면 untrimmed video로 구분하고 있습니다.

이번 글에서는 세상에서 발생한 다양한 사건들이 포함된 untrimmed video로 구성된 FIVR 데이터셋을 활용한 동영상 검색을 다룹니다. 같은 화재라는 사건 카테고리 안에 포함되어 있어도, 어디서 불이 났는지에 따라서 서로 다른 영상으로 구분되기 때문에, 영상의 전반적인 특징들을 잘 파악해야 합니다.
동영상 검색의 필요

그림 3. 텍스트 검색과 영상 검색의 차이
많은 사람들이 영상 검색이라고 하면, 유튜브에서 영상을 찾기 위한 “텍스트”를 이용한 영상 검색을 떠올립니다. 이 검색 같은 경우에는 특정 키워드를 입력했을 때, 기 생성된 다양한 메타데이터를 활용하여 검색을 수행합니다. 하지만 video retrieval에서는 영상을 찾기 위해 “영상”을 이용합니다. 영상 내에 포함되어 있는 콘텐츠를 딥러닝 모델이 학습하여 검색을 수행하기 때문에, 생성되지 않은 메타데이터에 대한 특징들도 포함한 검색을 수행할 수 있습니다.

비슷한 예시로 SBS에서는 이미지 기반의 동영상 검색 시스템을 도입하여 활용하고 있다고 합니다. 방송국에서 자료화면 등을 찾을 일이 많은데, 이러한 시스템 덕분에 빠르게 찾을 수 있어 업무 효율성이 증가했다고 하는데요. 비록 해당 시스템에서는 동영상을 활용하지는 않았지만, 기술 수준이 조금 더 발전된다면 이러한 시스템에 동영상을 입력할 수 있을 것이라고 기대하고 있습니다.
비디오를 표현할 수 있는 서술자(descriptor) 생성
이미지 검색에서는 특정 이미지를 잘 표현할 수 있는 서술자를 잘 생성하는 것이 연구의 핵심이라고 볼 수 있습니다. 이때 서술자는 딥러닝 모델이 특정 입력을 대표할 수 있도록 만든 벡터를 서술자라고 부르는데요. 비디오 검색에서도 동일하게 이 서술자를 잘 추출하는 것이 매우 중요합니다.
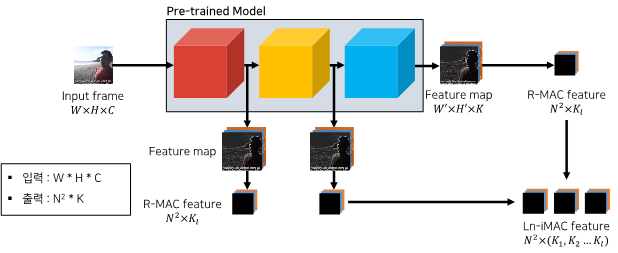
최근 연구들에서 많이 활용되고 있는 서술자 생성 방법론으로는 위의 그림과 같이 Ln-iMAC이라는 방법론이 있습니다. 해당 방법론의 경우에는 특정 프레임에서 서술자를 추출할 때, 딥러닝 모델의 중간 계층의 출력 값을 포함한 다양한 레이어에서 서술자를 추출하고, 이를 병합하여 최종 서술자를 생성합니다. 그럼 왜 중간 계층의 출력 값도 활용할까요? 이는 딥러닝 모델의 초기 레이어와 후기 레이어가 가진 정보의 차이가 있기 때문입니다. 따라서 다양한 정보량을 가진 서술자를 생성하기 위한 방법이라고 보면 좋을 것 같습니다. 또한, 중간 계층에서 서술자를 추출할 때에도 N*N의 영역(Region)을 지정하여 공간 정보를 살려 추출하는데요. 이러한 방식을 모두 조합하여, 보다 많은 정보량을 가지는 서술자를 생성합니다.
대표 연구
비디오 검색 연구는 영상 간의 유사도를 계산할 때 사용하는 서술자의 단위로 연구를 구분합니다. 따라서 크게 2가지 연구로 구분할 수 있는데요. 프레임 기반 방법론(Frame-level feature based method)과 비디오 기반 방법론(Video-level feature based method)이 있습니다.
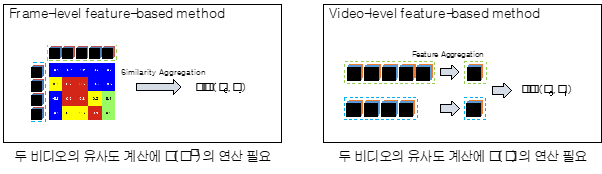
이렇게 구분되는 이유는 서술자의 단위에 따라 속도와 정확도 측면에서 큰 차이가 발생하기 때문입니다. 먼저 프레임 기반 방법론의 경우에는 두 영상의 유사도를 계산할 때, 모든 프레임 간의 유사도를 계산하게 됩니다. 따라서 유사도 계산에 필요한 연산량이 그만큼 많아지고, 더 많은 정보를 가진 채로 계산을 수행하기 때문에 정확도가 높습니다. 반면에 비디오 기반 방법론의 경우에는 두 영상의 유사도를 계산할 때, 모종의 방법으로 생성된 단일 벡터를 활용하여 유사도를 계산합니다. 따라서 더 적은 정보량을 가진 벡터로 단 1회의 연산으로 유사도를 계산하기 때문에, 더 빠른 대신 정확도가 낮다는 특징이 있습니다. 각 방법론의 일반적인 특징이 이러하다는 점을 설명 드리면서, 이번 글에서는 각 방법론의 대표 연구를 소개해드리겠습니다.
ViSiL: Fine-grained Spatio-Temporal Video Similarity Learning
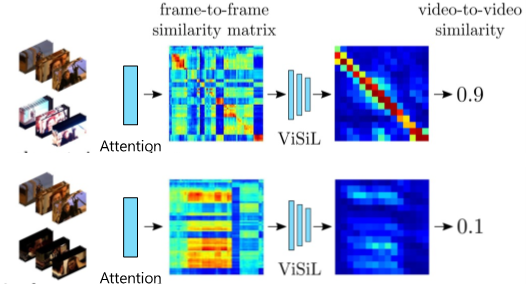
프레임 기반의 대표적인 방법론인 ViSiL은 크게 2가지 모듈(Attention module, Video comparator module)로 구성되어있습니다. Attention module을 거친 두 영상의 서술자를 활용하여 프레임 간의 유사도를 계산하고, Video comparator module을 거친 이 프레임간 유사도를 활용하여 영상 단위 유사도를 계산하는 것을 볼 수 있습니다. 유사도 계산에서는 chamfer similarity를 활용하는데요. 검색에서 활용하는 Ln-iMAC의 서술자에서는 영역을 지정하고 추출하여 공간 정보를 보존하였고, 이 영역 단위로 유사도를 계산하는 방법이 chamfer similarity입니다.

이렇게 유사도가 영역 단위로 계산되기 때문에, 특정 서술자에서 정보량이 없는 영역을 억제하는 것이 attention module의 목표입니다. [그림 8]의 야구장에서 타자가 찍힌 이미지를 예시로 설명해보겠습니다. 이 이미지에서 9번 영역의 경우에는 바닥(흙)을 찍고 있는데요. 이러한 영역들은 야구 타자가 포함된 2,5,8번 영역에 비해 상대적으로 중요하지 않은 영역이 됩니다. 따라서, 이러한 영역들이 유사도 계산 과정에서 더 낮은 값을 가지도록 억제합니다.

이렇게 attention module이 적용된 서술자를 이용하여 프레임 단위 유사도를 계산하고 이를 취합하게 되면 [그림 9]의 왼쪽 이미지와 같은 프레임 단위 유사도 행렬이 계산됩니다. Video comparator module은 이 유사도 행렬에서 특정 패턴을 찾는 것이 목표입니다. 이는 유사한 영상에서 보여지는 특징에서 기인하는데요. 만약 두 영상에 유사한 구간이 존재한다면, 구간 내의 프레임들은 서로 유사하기 때문에, 유사도 행렬을 그렸을 때 네모 패턴을 보이게 됩니다. 따라서, 이러한 두 패턴을 찾고 강조하는 것이 이 모듈의 목표가 됩니다. 실제로 video comparator module의 출력이 [그림 9]의 오른쪽 행렬이 된다면, 최종 영상 단위 유사도는 이 행렬을 취합하여 계산됩니다.
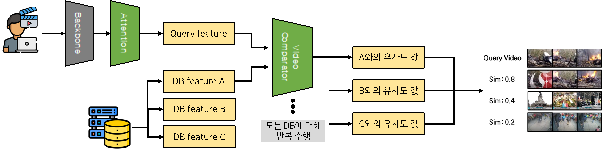
특정 영상을 검색하는 시나리오에서는 [그림 10]과 같은 구조를 가집니다. 데이터베이스에 저장되어 있는 동영상에 대해서는 attention module을 거친 서술자들을 미리 저장합니다. 사용자가 특정 영상을 검색하기 위해 입력하면, 백본 모델에서 Ln-iMAC과 attention module을 거쳐 서술자를 생성합니다. 그 다음 최종적으로 영상 단위 유사도를 계산하기 위해서는 video comparator module을 적용합니다. 이 계산하고자 하는 영상의 개수만큼 반복합니다. 종합적으로 앞서 설명한 것처럼 두 영상의 유사도를 계산하기 위한 연산량이 많고, 반복적인 모델 연산이 필수적인 구조이기 때문에 동작 속도는 느리지만, 정확도가 높다는 특징을 가집니다.
VVS: Video-to-Video Retrieval with Irrelevant Frame Suppression
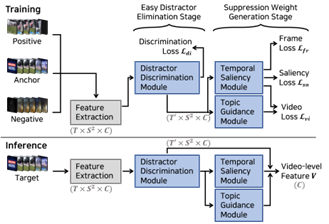
비디오 기반의 대표적인 방법론인 VVS는 2개의 스테이지(Easy distractor elimination stage, Suppression weight generation stage)와 3개의 모듈(Distractor discrimination module, Temporal saliency module, Topic guidance module)로 구성되어 있습니다. VVS는 앞서 설명한 ViSiL과는 다르게 단일 서술자를 활용하여 최종 영상 단위 유사도를 계산하는 방법론이기 때문에, 모델의 전반적인 목표가 단일 서술자를 생성하는데 어떤 프레임을 어떤 비율로 가져갈 것인지를 계산하는 것에 있습니다.

먼저 Easy distractor elimination stage의 Distractor discrimination module(DDM)는 영상 내에서 불필요한 프레임들은 단일 벡터를 생성하는데 활용하지 않겠다는 목적을 가진 모듈입니다. 이때 불필요한 프레임은 magnitude라는 값을 이용하여 계산합니다. [그림 11]에서 위쪽 프레임들이 magnitude가 낮은 경우이고, 아래쪽이 magnitude가 높은 경우인데요. 천천히 프레임들을 둘러보면 magnitude값이 낮으면 단색에 특정 패턴을 가진 프레임들이며, 높아지면 높아질수록 시각적인 특징이 있다 정의할 수 있습니다. 따라서 DDM의 목표는 이러한 프레임들을 구분하여, distractor로 구분될 경우 다음 단계로 넘어가지 않게 배제하는 것이 목표입니다.

이광진
연구원, AI 연구 개발팀
세종대학교 지능기전공학과 석사
세종대학교 Robotics and Computer Vision Lab에서 동영상을 활용한 동영상 검색 연구에 기반하여, 다양한 영상 기반의 연구 및 프로젝트를 수행하였다. 현재 테스트웍스 AI 개발팀에서 Document understanding과 관련된 기술을 연구하고 있다.