
AI 업계에서 LLM의 인기는 대단합니다. 연구용과 상업용을 가리지 않고 다양한 모델이 계속 개발되고 훈련되어 세상에 공개되고 있습니다. 그런데 그렇게 만들어진 제품이 시장에서 큰 영향력을 발휘하고, 작성된 논문에 의의가 있으려면 다른 모델보다 성능이 더 좋아야 합니다.
우리가 흔히 생각하는 분류형 모델이라면 얼마나 맞췄는지 점수를 매기면 성능 우위 평가를 쉽게 할 수 있습니다. 그런데 LLM은 모델에서 생성된 결과가 문장입니다. 같은 내용을 담고 있다고 하더라도 이를 표현하는 방법은 한 가지에 그치지 않습니다. 준비했던 정답이 “저기에 한 여자가 앉아 있다.” 라고 할 때, 모델이 “저기에 사람이 있다.”라고 한다면 과연 우리는 몇 점을 줘야 할까요?
이번 연재에서 다룰 내용은 이렇게 경계를 긋기 애매한 언어 모델의 성능 평가를 위해 개발되어 사용되고 있는 평가 법입니다. 그중에서도 사람이 개입하지 않고 기계적으로 점수를 산출할 수 있는 평가 법들에 대해 알아보려고 합니다.
[BLEU: BiLingual Evaluation Understudy Score]
가장 유명하고 가장 자주 쓰이는 평가 지표로 BLEU가 있습니다. 이 평가 지표는 처음에는 기계 번역의 품질을 측정하기 위해 개발된 것이나, 활용 범위가 넓어져 번역 뿐 아니라 정답 문장과 비교를 하는 다양한 과제에서도 사용되고 있습니다.
방법은 간단합니다. 생성된 문장의 n-gram 중에서 정답 문장에도 존재하는 n-gram이 몇 개인지 세는 것입니다. 분류 과제에서 성능평가를 하는 것과 계산 방법이 비슷해 n-gram precision이라고도 합니다.

n-gram에서 n의 값을 하나가 아니라 여러 개를 사용하여 n-gram precision을 계산한 후, 각 값의 기하평균 값을 사용합니다. 필요하다면 여기에 가중치 Wn을 부여할 수도 있습니다. 우리가 자주 사용하는 nltk 라이브러리의 경우, 별도의 옵션을 주지 않으면 unigram(1)부터 4-gram까지 구한 후, 동일한 가중치로 평균을 냅니다.
이렇게 나온 값을 그대로 사용하면 좋지만, 여기에는 문제가 하나 있습니다. 다음의 예시를 볼까요.
생성된 문장: 나는 고양이
정답 문장: 나는 고양이 두 마리를 기른다.
생성된 문장은 절대 좋은 문장이라고 할 수 없습니다. 제대로 완성되지도 않은 짧은 문장입니다. 그런데 1-gram 기반으로도 2-gram 기반으로도 이 문장의 BLEU 점수는 100%가 나옵니다. 왜냐하면 계산식의 분모가 생성된 문장의 n-gram 수이기 때문입니다. 따라서 너무 문장이 짧은 경우 점수가 낮아지도록 보정해야 합니다. 이 때 사용하는 보정을 Brevity Penalty라고 합니다. 생성된 문장의 길이를 c, 정답 문장의 길이를 r이라고 하면 Brevity Penalty는 다음과 같이 계산합니다. (정답 문장이 여러 개일 경우 c와 가장 가까운 값을 사용합니다.)
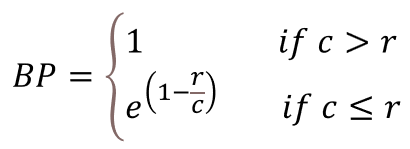
이렇게 BP까지 적용한 최종적인 BLEU 점수 식은 다음과 같습니다.
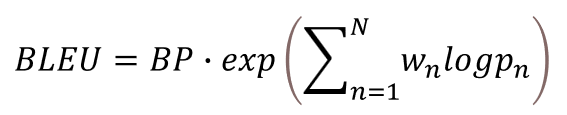
[METEOR: Metric for Evaluation of Translation with Explicit ORdering]
BLEU가 가장 대중적으로 사용되는 평가 지표이긴 하지만, 완벽한 평가 지표는 아닙니다. 연구자들은 BLEU보다 좀 더 문장의 질을 잘 평가할 수 있는 다른 평가 법을 연구해 METEOR라는 평가 법을 공개했습니다.
가장 먼저 unigram 단위에서의 recall과 precision의 조화평균값을 구합니다. 다만 조화평균을 구할 때 recall과 precision의 가중치를 1:9로 합니다.
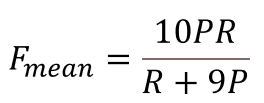
다음으로는 METEOR에서 새롭게 등장하는 개념인 Chunk를 만들어주어야 합니다. 이를 위해서는 생성된 문장과 정답 문장 사이에 같은 unigram들을 짝을 지어줘야 합니다. 이 unigram들은 일대일로만 연결되어야 하며, 대응하는 짝이 없을 경우 아예 연결하지 않습니다. 그렇게 짝을 짓고 나서, 양쪽 문장에서 연속된 단어들이 똑같이 등장할 때 그 연속된 단어들을 묶어서 Chunk라고 합니다. 짝을 짓는 방법은 보통 여러 가지가 있는데, 이 중에서 Chunk의 개수가 가장 작아지도록 합니다. 짝지어진 unigram 쌍의 개수를 U_m, 그리고 최소가 된 Chunk의 개수를 c라고 합니다.

Chunk의 개수가 너무 많으면 얼핏 겹치는 단어는 많아 보여도 순서가 서로 뒤죽박죽이라 의미가 다르거나 말이 되지 않는 문장일 확률이 높습니다. 따라서, Chunk의 개수가 많아질수록 값이 낮아지는 널티 값을 도입하고, 최종 METEOR 값을 계산합니다.
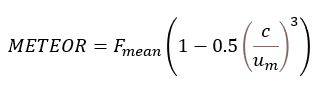
자연어처리에 컴퓨터 비전이 함께하는 멀티모달 모델이 등장하면서 새롭게 나타난 평가지표도 있습니다. CIDEr와 SPICE가 그 예입니다. 이 둘의 공통적인 특징은 바로 정답 문장이 하나가 아니라 여러 개라는 것을 전제로 한다는 것입니다. 사진에 대한 설명을 기술하는 이미지 캡션 과제에서는 보통 상황을 표현하는 방법이 여러 가지가 있기 때문에 정답 문장을 사진당 5개 정도씩 마련하는 편입니다. 그래서 평가할 때도 모든 정답 문장을 한꺼번에 고려합니다.
[CIDEr: Consensus-based Image Description Evaluation]
CIDEr 지표는 TF-IDF(단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency)를 기반으로 합니다. TF(단어 빈도)는 해당 n-gram이 정답 문장 각각에서 몇 번이나 등장했는지를 봅니다. 한 문장 안에 같은 단어가 여러 번 등장할 경우, 중요성이 높을 가능성이 크기 때문입니다. ID(Inverse Document Frequency)는 해당 n-gram이 정답 문장 중 몇 군데에서나 해당 n-gram이 등장하는지를 나타내는 DF에 역수와 log를 순서대로 취한 값입니다. 특정 단어가 여러 문서(사진)에서 공통적으로 발견된다면 오히려 핵심이 되는 단어가 아닐 수 있기 때문에, 역수를 취해주는 것입니다(log는 역수를 취했을 때 값이 너무 커지는 것을 방지하기 위한 것입니다).
이 TF-IDF 값을 생성된 문장과 정답 문장에서 n-gram(1≤n≤4)에 대해 실시한 후, 그 값을 벡터로 나타냅니다. 그리고 정답 문장과 생성된 문장의 코사인 유사도를 구한 뒤, 가중치를 적용하여(보통 균등) 평균을 내면 그것이 CIDEr 점수입니다.
[SPICE: Semantic Propositional Image Caption Evaluation]
SPICE (Semantic Propositional Image Caption Evaluation)은 지금까지의 평가지표와는 다르게 n-gram을 사용하지 않는 평가 지표입니다. 여기서는 정답 문장이 여러 개 있는 것에 착안하여, 정답 문장들의 단어들을 Object, Attribute Relation으로 구분하고 이 관계를 나타내는 그래프를 그립니다.
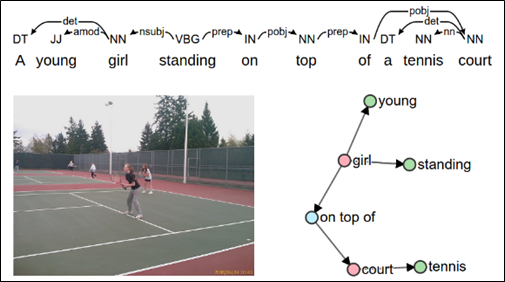
Source: Anderson, P., Fernando, B., Johnson, M., & Gould, S. (2016). Spice: Semantic propositional image caption evaluation. In Computer Vision–ECCV 2016: 14th European
Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14 (pp. 382-398). Springer International Publishing.
모든 정답 문장에 대한 분석을 같은 그래프에 계속 덧대면 하나의 큰 그래프가 될 것입니다. 마지막으로 생성된 문장에 대해서 같은 원리로 새 그래프를 하나 그린 뒤, 생성된 문장 그래프가 정답 문장들의 그래프와 얼마나 겹치는 부분이 있는지를 확인하는 것으로 유사도를 평가합니다.
이 방법을 이용하면 공통 부분이 많지만 전혀 다른 문장 쌍이나, 공통 부분이 전혀 없지만 내용이 유사한 문장 쌍에 대해 대응할 수 있게 됩니다. 하지만 반대로 이 단어들 사이의 관계에만 너무 집중해서 문법적으로 발생할 수 있는 오류를 놓칠 수 있다는 지적을 받기도 합니다.
기계적 평가는 사람이 개입하지 않고 알고리즘만으로 바로 점수를 계산할 수 있다는 점에서 어느 정도 객관성을 확보한 평가지표라고 할 수 있습니다. 하지만 최근 이러한 기계적 평가 지표가 정말 유의미한 평가인지에 대한 고찰이 이루어지고 있습니다. 어느 정도 참고용으로 볼 수는 있겠지만 이것이 100% 신뢰 가능한 평가 지표는 아니라는 것입니다.
2016년에 발표된 한 논문에서는 연구진이 실제로 사람들에게 생성된 문장에 대한 점수를 매겨보도록 하고, 이를 기계적 평가지표들과 비교했습니다.
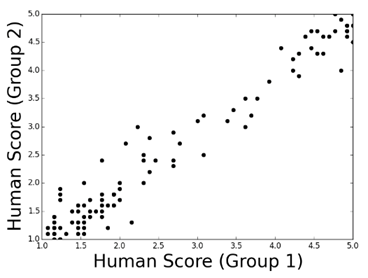
사람이 매긴 점수끼리의 비교에서는, 한쪽 그룹에서 매긴 점수가 높으면 다른 쪽 그룹에서 매긴 점수도 비슷하게 높은 점이 관찰되었습니다. 각 그룹의 평가 결과가 서로 유의미한 상관관계를 보인 것입니다.
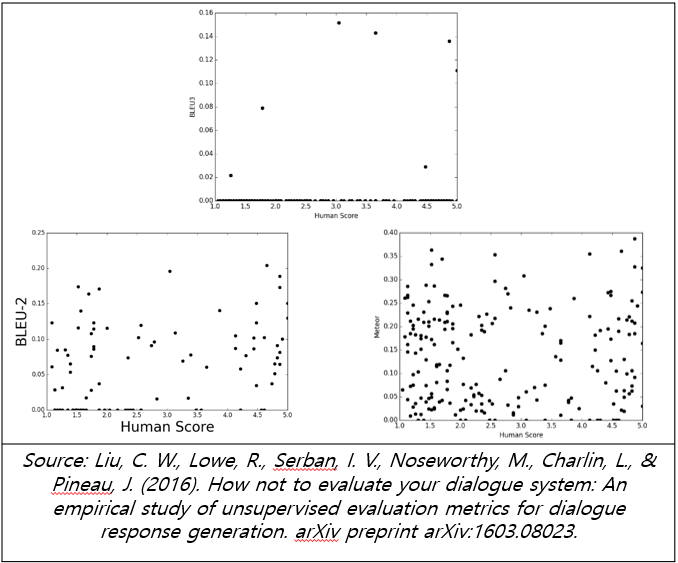
하지만 기계적 평가지표는 사람의 평가와 같이 보았을 때 많이 다른 결과를 보였습니다. 먼저 3개의 연속된 토큰을 보는 BLEU-3의 경우, 애초에 세 개의 토큰이 똑같이 나열된 경우가 많지 않아 대부분의 점수가 0점으로 나왔습니다. 비교 이전에 제대로 채넘할 수 없는 평가 체계라는 것입니다. BLEU-2나 Meteor 점수는 0점의 개수는 많이 줄어들었지만, 사람 그룹끼리의 비교 때처럼 분명한 상관관계를 보이지 않았습니다. 즉, 사람이 좋게 평가한 문장도 평가지표 상으로는 낮은 점수가 나오고, 평가 지표가 높았던 문장이 사람이 보기에 이상한 경우가 많다는 것입니다.
그래서 최근 LLM의 성능을 평가할 때는 지금까지 살펴본 기계적 지표뿐 아니라 다른 평가 방법을 이용하기도 합니다. 다음 글에서는 최근 LLM의 경쟁에 불을 지피고 있는 벤치마크를 이용한 평가와, 사용자 입장에서 바라보는 사람에 의한 평가에 대해 알아보도록 하겠습니다.

한승규
연구원, AI 연구 개발팀
고려대학교, 컴퓨터학과 석사
고려대학교 자연어처리 및 인공지능 연구실에서 자연어처리 관련 연구를 하였으며, 다양한 데이터 셋으로 모델을 파인튜닝하는 프로젝트들을 진행했다. 현재는 테스트웍스 AI 본부에서 LLM과 Multi-modal 관련 연구를 진행하고 있다.