

Changsin Lee l Tech Evangelist l Testworks
The technological advancement of Artificial Intelligence is impacting many areas of our lives like health care, manufacturing, entertainment, and farming. The development of AI, however, also comes with new problems. Bias, accuracy, privacy, and security issues in recent years made the general public worry about the ethical and legal consequences of AI.

To address these concerns, many government bodies began to draft a legal framework around trustworthy AI so as to make it possible to regulate AI without hindering its development. Just as they did for data protection with GDPR (General Data Protection Regulations) in 2016, the EU led the world on Trustworthy AI by publishing Ethics Guidelines for Trustworthy AI (2019), White Paper on Artificial Intelligence — A European approach to excellence and trust (2020), and A European Strategy for Data (2020). In the US, a similar measure exists, namely, Algorithm Accountability Act (2019).
Spurred on by these regulatory efforts, researchers began to work on various aspects of trustworthy AI. In this article, I will introduce some of the existing literature on Trustworthy AI and suggest a framework to build Trustworthy AI. The main point of my argument is that Trustworthy AI needs to be tackled in three different ways corresponding to the three components of AI: the model, the data, and the code and that the data quality is the cornerstone of building Trustworthy AI.
EU’s Risk-based Approach to Trustworthy AI
EU’s Ethics Guidelines for Trustworthy AI (2019) defines Trustworthy AI to be:
- Lawful: respecting all applicable laws and regulations.
- Ethical: respecting ethical principles and values.
- Robust: both from a technical perspective while taking into account its social environment.
Under this broad definition, four ethical principles are drawn:
- Respect for human autonomy
- Prevention of harm
- Fairness
- Explicability
To apply these principles, the subsequent White Paper (2020) outlines a risk-based approach by categorizing AI into four categories:
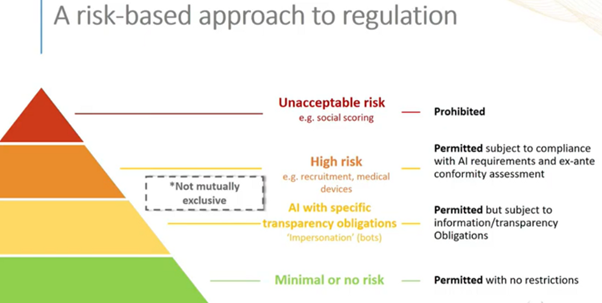
Of these, the focus is on High-Risk AI which includes medical devices, recruitment, education, biometric identification, law enforcement, etc. AI systems in these fields must assess risks and meet these requirements.
- High-quality data: Use high-quality training, validation, and testing data (relevant, representative, etc.)
- Document & logging: Establish documentation and design logging features (traceability & auditability)
- Transparency: Ensure an appropriate degree of transparency and provide information on how to use the system
- Ensure human oversight
- Ensure robustness, accuracy, and cybersecurity
The contribution of the EU’s approach to Trustworthy AI is that it made the nebulous concept of Trustworthy AI concrete and applicable in assessing real AI applications. Requirements like robustness, transparency, and explicability can be found in other research papers and requirements for Trustworthy AI too. For instance, in Trustworthy AI: A Computational Perspective (2021), we find the requirements that are largely overlapping with the EU’s:
- Safety & Robustness
- Non-discrimination & Fairness
- Explainability
- Privacy
- Accountability & Auditability
- Environmental Well-Being
EU requirements highlight human-centered AI and the quality of data.
Limitations
While EU regulations provide a good framework for Trustworthy by AI, there are a few limitations. First, the regulations do not take into account the highly experimental nature of AI development. Traditional software is developed after gathering requirements in the form of a tech spec and a design spec is written. An AI system, on the other hand, involves many rounds of trials and errors, sometimes resulting in completely abandoning a model in favor of better architecture. A slight perturbation on hyperparameters or training data distribution might lead to completely different behavior. It is hard to prescribe requirements when the prediction behavior is constantly evolving.
Second, the regulation calls out requirements without providing adequate guidelines on how to prioritize and make tradeoffs for different AI systems. For instance, accuracy might be more important for medical devices than cybersecurity but for a face recognition system, fairness is probably more relevant.
Third, the regulation sets up requirements without specifying the methods and metrics to meet. For instance, accuracy for a face recognition system might be different from an education AI. We are told about the acceptable level of accuracy it is for each type of system.
The regulation is an attempt to control a field that is in active development so we expect that the details and refinements will be developed in a few years. In the meantime, we need a working framework that we can use o develop Trustworthy AI. Below is my suggestion.
Model, Data, and Code
AI is not a single monolithic entity. What the end-users see is just software but it can be broken into three components:
- Model: The model includes the algorithm, architecture, hyperparameters, and weights. They are housed in the form of software but unlike traditional software products, an AI system behaves very differently depending on the model, and thus it is better to separate the model from the code (software).
- Data: Once the model is decided, the performance of an AI is largely dependent upon the data. The importance of data cannot be emphasized enough as the famous dictum, ‘Garbage in, garbage out’ shows. More recently, the data-centric approach focuses on the data to improve the performance of AI. I want to argue that the data-centric approach is needed for Trustworthy AI as well.
- Code: The code is the software container that the model is shipped. In most AI literature, the model includes the software as well, it is better to separate the software from the model-proper. The reason is that we have already well-established methodologies and standards for traditional software: e.g., Trustworthy Computing. AI models, on the other hand, behave quite differently. Simply put, traditional software is rule-based no matter how complicated it might be. AI models, on other hand, cannot be understood so easily and thus requiring them to be transparent and explainable.
By breaking AI into three components, it allows building Trustworthy AI using appropriate methods for each. As illustrated above, by focusing on the software aspect of AI, we already know how to best test and establish quality through Trustworthy Computing criteria and methods. The four pillars of Trustworthy Computing are Reliability, Security, Privacy, and Business Integrity which are readily applicable to Trustworthy AI as well. Business Integrity means being responsible and transparent so they match Trustworthy AI requirements.
For the model, the primary requirements are transparency in the sense of being interpretable and explainable. For traditional machine learning models, the transparency requirement can easily be achieved by showing the algorithms and mathematical functions used.
For Deep Learning models, however, it is not quite easy because of the complexity of the network architecture and training process. Oftentimes, the model is viewed as a ‘black box’ and you can see nothing but the input and output. For these ‘opaque’ models, establishing trust cannot resort to interpretability or explainability. Instead, you have to rely on other requirements like robustness and diversity to ensure that the AI can work in all intended cases.
Data-Centric Approach to Trustworthy AI
The above discussion leads to the claim that data is the most important component in building trustworthy AI. There are three reasons for the conclusion.
First, as we have seen above, the complexity of many AI models defies the requirement for transparency.
Second, the data-centric AI showed how data quality affects AI performance, and thus to meet many of the trustworthy requirements like accuracy, fairness, and accountability, the best method seems to be focusing on data quality.
Third, validating AI for trustworthiness requires testing it against all possible intended scenarios. Testing AI requires testing data. In fact, unless the testing data reflects the distribution of real-world data and the training data, there is no way and no point of testing it.
The corollary is that quality data is the cornerstone of Trustworthy AI.
Quality Data in Stages
Having defined Trustworthy AI data in terms of data quality, the next question is how to validate quality. The EU risk-based approach requires a trustworthy assessment for High Risk AI before release. A potential problem with this approach is the tendency to consider quality as a one-time checklist.
In the traditional waterfall model of software development, testing is considered as ‘after-the-fact’: the last step you do after you are done with the development of the software. The sequential nature of development and the rigidity of the entire process made the waterfall model fall out of favor when software became more service-oriented where user requirements and designs change all the time.
As we have seen, though an AI is shipped as software, its behavior cannot be described by predetermined rules. It resembles an organism that is constantly evolving and learning, especially with the recent prevalent use of the MLOps pipeline.
In software development, the agile movement largely replace the waterfall model and culminated in developing DevOps pipelines. In AI development, though it is still developing, a similar effort is underway. Corresponding to agile DevOps pipelines, AI is developed in iterative MLOps pipelines. A typical MLOps pipeline looks like this:
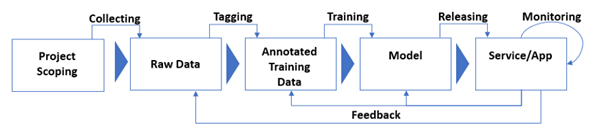
Given the iterative nature of AI development, it makes sense to think Trustworthy AI in terms of stages and so data quality also needs to be done in stages.
The result is data quality defined in stages like the followin
- Scoping: During the project planning stage, target dataset quantity and distribution (how class data is distributed), as well as quality metrics, are to be defined and planned for.
- Collecting: Based on the target quantity and distribution, raw data are gathered that are reliable, representative, balanced, diverse, and fair.
- Reliable: data come from legitimate sources and can be traced back.
- Representative: class definitions and their distributions reflect the target domain.
- Balanced: being representative of the target domain might not achieve the target accuracy for rare objects. Oversampling of minor class objects, undersampling of bigger class objects, or augmentation might be needed to have a balanced dataset for the target accuracy.
- Diverse: To make AI work well for a diverse set of cases, the data need to be as diverse as possible without duplicates.
- Fair: Data should be checked for implicit and explicit biases. For a High-Risk AI, it is imperative that you prepare test data that can detect biases in the model.
- Labelling: Labeling refers to the annotations and reviews done by humans. The process is labor-intensive and susceptible to human errors and inconsistency so the goal is to build a dataset that is accurate and consistent.
- Accurate: Annotation is done accurately according to the specified guidelines.
- Consistent: The annotation results from different annotators are within the acceptable range of accuracy.
- Training: Training is largely in the realm of the model trustworthy so the defining criteria are transparency and explainability.
- Transparency: the model’s architecture and the cause-and-effect relationship between input and output can be understood. A similar term used in the literature is interpretability, but I am using transparency instead to emphasize the traceability of data (where data came from and how they were modified and moved) as well as the training process itself (hyperparameters, validation, and test sets, etc.)
- Explainability: Explainability means being able to explain the inner workings of AI when making decisions. As noted earlier, this requirement is not always easy to achieve for complex and opaque models and might need to be traded off for other requirements like accuracy.
- Testing and Releasing: After training is done and the model behavior is verified, the AI system needs to be tested as software. Trustworthy Computing requirements of reliability, security, privacy, and business integrity should be used as well as testing for accuracy, fairness, and robustness.
- Monitoring and feedback: AI development is an iterative process so after releasing the product, there should be a mechanism to monitor its behavior and re-evaluate and train the model accordingly. The major requirements are traceability and accountability.
- Traceability: Given that it is impossible to test all possible scenarios during testing, the goal is to trace and investigate how data flows and affects the AI’s decision-making process in production.
- Accountability: For every decision, it should be possible to find the data, the component, or the design that is responsible.
The iterative nature of AI development means that building Trustworthy AI is really a process, not a checklist. Through continuous monitoring, feedback, and retraining, new data are added to the data set which in turn makes the AI more robust, accurate, and fair.
Conclusion
This is a survey article on the topic of Trustworthy AI. EU’s guidelines for ethics and data strategy laid out a good foundation for building Trustworthy AI but we also examined some of its limitations. The data-centric approach to Trustworthy AI is an attempt to break it down into different components and apply well-tested methods for each. Model, data, and code are the three components and data play a pivotal role in all stages of AI development. AI is still new to us and we just began the process of understanding its capability, legal, and ethical implications. Building trust takes time even between two human beings so it is important that we continue to improve the process and the methods of building Trustworthy AI.