
개요
딥러닝 모델은 대부분 오픈소스로 공개되어 있어서 인공지능 분야의 지식을 가진 개발자라면 관련 논문을 읽어보고 Github에서 구현된 소스를 찾아 구동하면 어렵지 않게 모델을 만들고 사용할 수 있다. 딥러닝 모델의 성능을 결정짓는 것은 해당 모델의 신경망 네트워크를 이루는 Weight값이며, 이는 훈련을 통해 결정되므로 결국 품질 좋은 데이터 확보가 인공지능 모델을 만드는데 제일 중요한 셈이다.
딥러닝 모델 훈련을 위해서는 많게는수십만 장에서 수백만 장에 달하는 데이터가 필요하며, 이 많은 데이터를 사람이 모두 수동으로 가공하기에는 리소스 낭비가 심하고 단순 반복적이며 비효율적인 작업이다.
효율적인 가공 작업을 위해서는 기존에 개발된(또는 가공 프로젝트 진행 중 신규 개발된) 자동화 모델을 이용하여 1차적으로 라벨링을 진행 후, 자동 라벨링된 결과를 보고 사람이 수정하거나 보완하는 등의 2차 가공 작업을 진행한다. 그리고, 최종적으로 검수 작업을 통해 고품질의 가공 데이터를 확보한다.
가공 자동화 모델을 이용하면 단순 가공 리소스를 줄이고 2차 가공 및 검수 리소스를 늘려서 데이터의 품질을 높이는데 집중할 수 있다.

자동화 모델
인공지능 데이터 가공 분야에 있지 않다면 가공 자동화 모델이라는 말은 조금 낯설면서도 의미가 모호해 보일 수 있다. 딥러닝 모델을 훈련하기 위해 데이터를 가공하는데 이 데이터를 가공하기 위해서 딥러닝 모델을 사용한다는 게 마치 닭이 먼저냐 달걀이 먼저냐 같은 상황일 수 있기 때문이다. 사실상 가공 자동화 모델과 이를 이용한 데이터로 훈련한 모델은 동일하다고 생각하면 된다. 다만 가공 자동화 모델은 1차 가공 작업을 하기 위해 제한된 데이터를 이용하여 빠른 시간내에 적당한 성능으로 만들어진 반면 실제 현업에서 사용하기 위해 만드는 모델은 성능을 극한까지 끌어올려야 하기 때문에 최적화를 위해 다양한 Hyper-Parameter를 변경하면서 많은 시간 동안 수많은 테스트를 거쳐 만들어진 다는 차이점이 있다.
현재 테스트웍스에서 수행하는 가공 프로젝트의 대부분은 80%정도가 영상 기반의 데이터로 생산성 향상 및 품질 확보를 위해 이미지 데이터 위주의 자동화 모델을 개발 및 확보하여 운용하고 있다. 텍스트나 음성 데이터의 경우 프로젝트를 통해 맞춤화시킨 음성전사 툴 등을 활용하고 있다.
자동화 모델 현황
테스트웍스에서는 자율주행, 인도보행, 의료, 보안 등 7개 분야에서 20개의 카테고리로 대략 260여개의 객체를 인식할 수 있는 자동화 모델을 개발하여 가공 작업에 사용하고 있다.
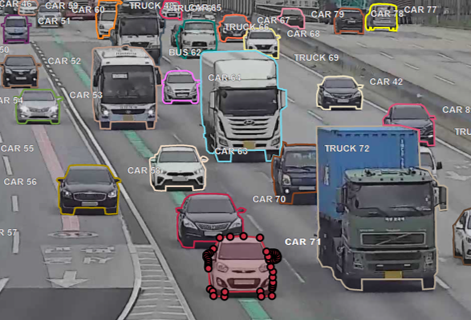
1. Object Detection
객체 인식(Object Detection) 모델은 객체의 종류와 사각형 기반의 위치를 찾아주는 모델로 아래 자사의 블랙올리브 화면과 같이 대상 객체에 인접한 Bounding Box를 그려준다.
Object Detection 모델은 CNN 기반의 Classification 부분과 객체의 위치를 검출하는 Localization 부분으로 이루어지며, 이 두 모듈을 어떻게 구성하는지에 따라 1-Stage Detector와 2-Stage Detector로 구분하고 있다.

2-Stage Detector는 속도는 느리지만 정확도가 높고, 1-Stage Detector는 속도는 빠르지만 정확도가 상대적으로 낮은 모델이었으나 최근엔 1-Stage Detector의 정확도가 많이 향상되어 구분이 모호해지고 있다.
대표적인 객체 인식 모델
– 2-Stage Detector: Fast RCNN, Faster RCNN, FPN(Feature Pyramid Network)
– 1-Stage Detector: YOLO, SSD(Single Shot MultiBox Detector), RetinaNet, CenterNet
2. Semantic Segmentation
이미지 내에 있는 객체들을 의미 있는 단위로 분할하는 것을 말하며, 픽셀 단위로 예측하는 것을 말한다. 아래 왼쪽 이미지는 한국지능정보사회진흥원(NIA)의 “인도 보행 영상 AI 데이터” 과제에 주관 기업으로 사업을 진행하면서 수집된 이미지에 자동화 모델을 적용하여 장애인이 이동 가능한 영역을 분리하여 표시한 모습이다. Bounding Box 형태로 객체를 구분하는 Object Detection 모델로는 표현할 수 없는 형태이다.

대표적인 Semantic Segmentation 모델
– FCN(Fully Convolutional Network), U-Net, DeepLab, Mask RCNN
3. Key-Point
2020년 NIA “수어 영상 AI 데이터” 구축 프로젝트를 진행하는 동안 수어 인식을 위한 데이터로 사람의 얼굴, 바디 및 손가락까지 가공 작업을 진행했다. 수어 인식을 위해서는 정지된 이미지 한두장이 아닌 10초 이내의 연속적인 이미지(동영상)에 대한 가공이 필요하다. 예를 들어, 초당 30fps의 영상의 경우 300개의 이미지 작업을 해야 하므로 자동화 기능이 절대적으로 필요하다.
얼굴, 바디를 비롯해 손가락까지 Key-Point를 추출할 수 있는 모델은 많지 않지만, 이번 수어 영상 데이터 구축 프로젝트를 통해 CMU(Carnegie Mellon Univ.)가 개발 및 관리하고 있는 Openpose 모델을 이용하여 1차 자동화 가공을 진행하였다.
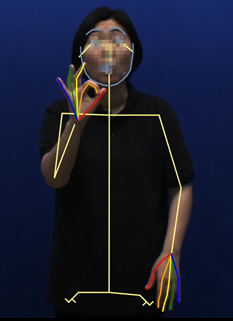
다만 왼손과 오른손이 겹쳐지는 상황 등에서 손가락 Key-Point 추출이 잘되지 않을 때가 있어 칼만 필터(Kalman filter) 등의 알고리즘을 이용하여 보정하며 사용하였다.
4. Semi-Auto Polygon
Polygon 가공 시 기 개발된 모델과 유사한 도메인의 객체인 경우 자동화 모델을 이용하여 1차 가공을 진행할 수 있으나, 그렇지 않은 경우 사람이 일일이 수동으로 객체 경계를 점을 찍어 polygon 가공을 해야 한다. 이는 숙련된 작업자라도 5분 이상 걸리는 까다로운 작업일 수 있다.
하지만, Semi-Auto Polygon 기능은 대상 객체를 사각형 형태로 선택하기만 하면 자동으로 배경을 분리하여 polygon으로 가공해 주기 때문에 가공 시간을 단축시킬 수 있다.


Salient Object Detection(SOD, 중요 물체 검출) 모델을 이용하면 영상 속에서 가장 중요하고 주목을 끄는 객체를 찾아내어 해당 객체의 전체 범위를 segmentation 해 줄 수 있는데, 이 기술을 이용하여 객체의 외곽선을 따라 polygon을 찾아낼 수 있다.

대표적인 SOD 모델
– BASNet, U2Net
5. De-Identification
인공지능을 위한 데이터셋을 구축할 때 민감하게 고려되는 부분은 개인정보 포함 여부이다. 사람이나 차량 등이 많이 포함된 자율주행 관련 데이터셋은 특히나 개인정보 비식별화에 주의를 기울여야 한다. 자칫 개인정보 관련 이슈가 생길 경우 해당 데이터뿐만 아니라 해당 데이터를 사용하여 훈련된 모델까지 영향을 받을 수 있기 때문이다.
테스트웍스에서는 개인정보 비식별 자동화 모델을 이용하여 사람의 얼굴이나 차량 번호판 등을 검출하고 Blur 처리를 통해 개인정보를 알아볼 수 없게 비식별화 처리를 하고 있다.

다만 현재의 비식별화 방식은 비식별할 영역을 찾고 Blur나 모자이크 방식으로 사람이 알아볼 수 없게 픽셀을 변형하는 방식을 사용하고 있지만 해당 방식으로 변형된 이미지는 추후 딥러닝 훈련이나 다른 방식의 이미지 분석에 사용하는데 성능 감소나 경우에 따라 아예 사용할 수 없다는 단점이 있다.
이러한 단점을 보완하기 위해 테스트웍스에서는 내년(2022년) 상반기를 목표로 GAN을 이용하여 이미지를 손상하지 않고 다른 모델에서도 사용 가능한 비식별화 솔루션을 연구하고 있다. (블로그 글 “데이터 시대의 초상, 비식별화 기술의 발전” 참고[ii])
모델 성능 비교 예시
모델 성능의 경우 여러 프로젝트를 통해 수집 가공된 데이터를 이용하여 딥러닝 모델을 전이학습(Transfer Learning)하기 때문에 공개된 모델보다는 높은 성능을 보인다. 아래 표는 객체 인식(Object Detection) 모델인 Faster RCNN의 주요 클래스에 대한 성능 비교 수치를 보여주고 있다.

자동화 모델 적용 효과
자동화 모델을 적용하여 전면 수동 가공 대비 약 53% 정도의 리소스를 절감할 수 있다.

정리
통계학 쪽에 “쓰레기를 넣으면 쓰레기가 나온다”라는 말이 있다. 좋지 않은 데이터를 사용하면 그 모델 또한 좋은 성능일리가 없다는 말이다. 인공지능 모델이 발전하면서 어느 정도 보완이 되고는 있지만 여전히 좋은 데이터셋은 고성능의 딥러닝 모델을 만들기 위한 필수 요소이다. 많은 양의 품질 좋은 데이터를 만들기 위해서는 가공 자동화 모델이 필수적이며 딥러닝 모델의 발전에 따라 가공 자동화도 점점 더 수월해질 것이다.
최근에는 딥러닝 모델을 이용한 가공 자동화 뿐만 아니라 검수까지 일정 부분 가능한 솔루션에 대한 연구가 다방면에서 진행되고 있다. 동일한 예측을 하는 여러 모델을 교차 검증하여 가공 결과를 검증하거나 객체 인식 모델 예측 값 중 Confidence 값을 이용하여 기준치 이하인 경우 사용자에게 알려줘서 해당 가공 건만 재검수를 하게 하는 방법 등이 있을 수 있다.
[i] 논문 U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection 문서 내 이미지 발췌
[ii] 데이터 시대의 초상, 비식별화 기술의 발전, 테스트웍스 김형복

임정현
수석 연구원, AI 연구 개발팀
조선대학교 컴퓨터공학 학사,
(前) 모바일리더 수석연구원, 삼성 Keis 개발 참여
15년 이상 윈도우 응용 프로그램을 개발하다 인공지능에 대한 관심으로 분야를 바꿔 딥러닝 모델을 이용한 지층 분석 시스템 개발을 시작으로 현재는 테스트웍스 AI 연구 개발팀에서 근무하며 Edge Computing 부분을 연구하고 있다.