
개요
딥 러닝 기술이 세계적으로 재조명을 받은 이후, 다양한 데이터에 대한 인공지능 연구 및 개발이 활발히 진행되고 있다. 그리고 현재까지 인공지능을 통해 가장 눈부신 성장을 이룬 분야 중 하나가 컴퓨터 비전이다. 이미지 데이터의 경우 시각적인 정보를 가지고 가장 직관적인 이해와 분석이 가능하므로 인공지능 모델 개발에 가장 많이 활용되고 있다. 원래 기계가 시각적인 정보를 해석하는 것은 매우 어려운 문제였지만, 딥 러닝 기술을 통해 이 문제가 어느 정도 극복되었기 때문이다. 현재는 이미지를 분류하는 Classification, 객체를 검출하는 Object Detection, 객체 영역을 찾는 Semantic Segmentation 등 이미지 데이터를 해석하고 이로부터 유용한 정보를 추출하는 기술이 눈부신 발전을 이루어 다양한 산업에서 사용되고 있다.
그렇다면 해석하고자 하는 정보가 3차원으로 확장되면 어떻게 될까? 이미지 데이터는 유용한 시각 정보를 가지고 있지만 2차원 데이터이기 때문에 3차원의 공간 정보를 얻는 것은 어렵다. 인공지능이 3차원 정보를 해석하기 위해서는 시각적으로 표현이 가능하면서도 3차원의 공간 정보를 담고 있는 데이터가 필요하다. 필자는 이 글을 통해 3차원 데이터 중 하나인 Point Cloud 데이터를 소개하고 이를 이용한 인공지능에 대해 소개하고자 한다.
Point Cloud 데이터

(출처 : 왼쪽 – Velodyne Lidar 홈페이지 , 오른쪽 – Intel Realsense 홈페이지 )
현실에 존재하는 3D 공간 정보를 시각적으로 표현할 수 있는 센서는 그리 많지 않다. 그리고 그 센서들이 3D 공간 정보를 표현하는 방법은 동일하다. 바로 위치 정보를 가진 수많은 점들을 모아서 공간을 표현하는 것이다. 그렇게 공간 정보를 가진 점들의 집합을 Point Cloud라고 한다. Point Cloud는 현실에서 3D 공간 정보를 수집할 때 얻을 수 있는 가장 기본적인 형태로, 현실에서 수집한 모든 3D 데이터는 Point Cloud를 기반으로 후처리 작업을 통해 얻을 수 있다.
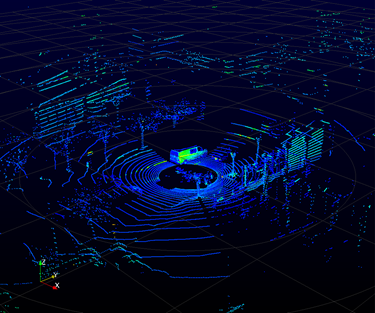
Point Cloud 데이터의 성질 및 3D 인공지능의 한계
현실에서 3D 공간 정보를 시각적으로 표현해 주는 데이터는 Point Cloud 데이터이다. 그렇기 때문에 3D 인공지능 연구 역시 Point Cloud 데이터 위주로 활발히 이루어졌다. 이미지 데이터와 마찬가지로 Point Cloud 데이터를 기반으로 한 Classification, Object Detection, Semantic Segmentation 등의 연구가 이루어졌다.
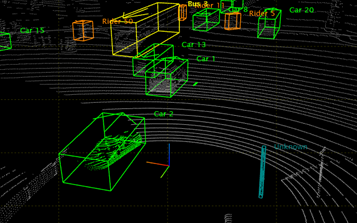
하지만 불과 몇 년 전 까지만 해도 Point Cloud 데이터를 다루는 딥 러닝 모델은 거의 찾아볼 수가 없었다. 이는 Point Cloud 데이터가 가진 몇 가지 성질에 의해 딥 러닝을 통한 해석이 매우 어려웠기 때문이다. 그래서 앞으로 소개할 Point Cloud 데이터를 다루는 최근의 딥 러닝 모델들을 이해하기 위해서는 Point Cloud 데이터가 가진 몇 가지 성질을 알아볼 필요가 있다.
정렬되지 않고 정형화되어 있지 않은 데이터
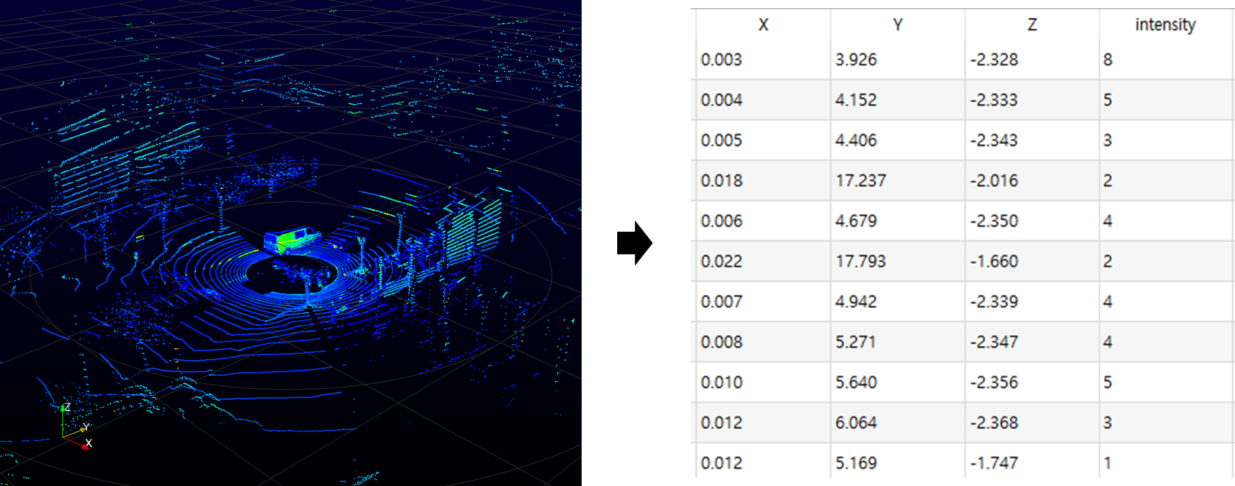
Point Cloud 데이터는 2D 이미지 데이터와 달리 정형화 되어있지 않다. 2D 이미지 데이터의 경우 정해진 격자 구조의 형태 안에 정보가 저장되지만, Point Cloud 데이터는 3D 공간상의 수많은 점들을 순서 없이 기록하는 방식으로 데이터가 저장된다. 이러한 데이터는 딥 러닝 모델에 있어서는 상당히 치명적이다. 객체의 형상, 점들 간의 상호작용 등 데이터가 가지고 있는 기하학적인 특성을 파악하기가 상당히 어렵기 때문이다.
이를 해결하는 방법으로 Point Cloud 데이터를 Voxel 형태의 정형화된 데이터로 전처리하는 방법이 존재한다. 하지만 이 방법 역시 다음 성질로 인해 3D 인공지능의 한계를 극복하는데 도움이 되지 못했다.
Sparse한 성질을 지닌 Point Cloud 데이터

2D 이미지 데이터가 정해진 격자에 pixel 값이 모두 존재하는 dense한 특성을 지녔다면, Point Cloud 데이터는 매우 sparse한 성질을 가지고 있다. 부연 설명을 하자면, 주어진 데이터의 3D 공간 안에는 Point들에 비해 빈공간이 상당이 많다는 것이다. 이러한 데이터는 크기에 비해 얻을 수 있는 유의미한 정보가 거의 없다. 이는 전 처리 작업을 통해 Point Cloud 데이터를 정형화 데이터로 변환하여도 동일하게 가지고 있는 성질이다.
이러한 데이터로 인공지능 모델이 학습 될 경우 유의미한 정보를 거의 얻기 어려우며, 학습 난이도만 올리게 된다. 이로 인해 3D 인공지능 모델은 좋은 성능을 보여주지 못했고, 오랜 시간 이 상태가 지속되면서 Point Cloud 데이터를 다루는 초기 3D 인공지능 모델은 한계를 보였었다.
Point Cloud 데이터를 다루는 3D 인공지능의 발전
이후 Point Cloud 데이터를 활용한 3D 인공지능 모델 연구는 Point Cloud 데이터가 가진 성질의 한계를 극복하는 방향으로 수행되었다. 단순히 Point Cloud 데이터를 전부 해석하는 것이 아니라, Point Cloud 데이터로부터 유의미한 정보를 추출하는 방식으로 연구가 이루어졌다. 그 결과 PointNet[1]을 시작으로 Point Cloud 데이터로부터 유의미한 정보를 추출하는 딥러닝 모델들이 좋은 성과를 보였다.
Point Cloud 데이터를 기반으로 좋은 성과를 보인 대표적인 딥러닝 모델들을 소개하면 다음과 같다.
PointNet
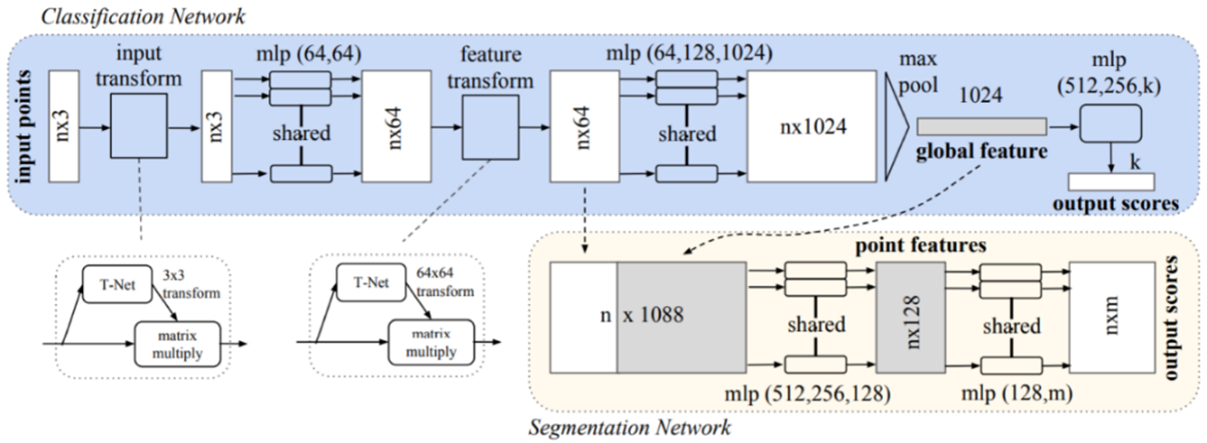
PointNet은 데이터 형태의 변환 없이 Point Cloud 데이터를 그대로 입력해 주어 학습하는 모델이다. Point Cloud 데이터가 순서 없이 나열된 비정형 구조를 띔에도 불구하고 Max Pooling, Spatial Transformer Network와 같이 데이터의 기하학적 성질을 유지할 수 있는 딥러닝 네트워크들을 소개하며 Point Cloud 데이터를 직접적으로 해석하는데 성공한 모델이다. 초기 PointNet 모델은 Point Cloud 데이터의 Classification, Semantic Segmentation 수행이 가능하다.
VoxelNet
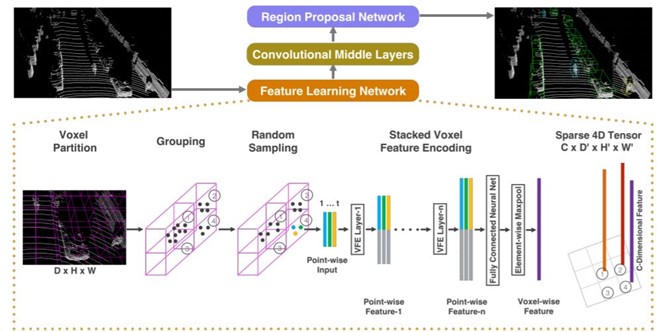
(출처 : Yin Zhou, et al. “VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection” 논문에서 발췌)
VoxelNet[2]은 Point Cloud 데이터로부터 Voxel Feature를 추출한 다음 이를 해석해 물체를 검출하는 3D Object Detection 모델이다. Voxel Feature는 데이터의 3차원 공간을 Voxel 단위로 나눈 후 각 Voxel 안의 점들을 Voxel Feature Encoding Layer라는 딥러닝 네트워크를 거쳐 Feature Map을 얻어낸 것이다. Point Cloud 데이터를 단순히 Voxel 형태로 전처리하는 것이 아니라 딥러닝 네트워크를 통해 Voxel 단위의 Feature Map을 만들어낸 것이 특징이다. 이러한 방법으로 얻은 데이터는 기존 방법보다 딥 러닝 네트워크를 통한 해석이 용이함이 실험을 통해 증명되었다.
SECOND
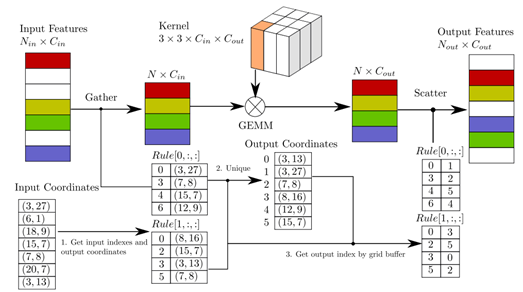
(출처 : Yan Yan, et al. “SECOND: Sparsely Embedded Convolutional Detection”논문에서 발췌)
SECOND(Sparsely Embedded Convolutional Detection)[3]는 VoxelNet과 기본적인 구조는 동일하지만 VoxelNet 내에 존재하는 Convolutional Middle Layer를 기존 CNN 대신 Sparse Conv Layer라는 레이어를 사용하는 것이 특징이다. 이 레이어를 SPCONV라고도 부른다. SPCONV는 반복되는 패턴에 대해 Rule을 설정하는 방식을 사용해 기존의 CNN에서 요구되는 계산 량을 대폭 낮췄다. 따라서 Point Cloud 데이터와 같이 매우 sparse한 데이터를 해석하는데 용이한 구조를 띄고 있으면서도 처리속도가 매우 빠르다.
PointPillars

(출처 : Anjul Tyagi. “PointPillars — 3D point clouds bounding box detection and tracking” Medium 글에서 발췌 )
PointPillars[4]는 Pillar라는 새로운 형태의 Point Cloud Encoder를 사용해 Point Cloud 데이터로부터 격자 형태의 Feature Map을 얻은 다음, 이를 해석해 물체를 검출하는 3D Object Detection 모델이다. VoxelNet이 3D Voxel 단위의 Feature Map을 얻어냈다면, PointPillar는 Point Cloud 데이터를 특정 시점에서 투영시킨 다음 2D 격자 단위의 Feature Map을 얻어낸 것이 특징이다. 이렇게 얻어낸 Feature Map은 이미지 데이터와 동일하게 2D CNN을 통한 데이터 해석이 가능해지므로 처리 속도가 상당히 빠르다.
이렇게 Point Cloud 데이터 형식이 가진 한계를 극복한 모델들이 몇 가지 등장하면서 Point Cloud 데이터 기반의 인공지능 모델의 연구도 이전보다 훨씬 활발해졌다. 현재는 앞서 소개한 모델들을 바탕으로 크게 두가지 방식으로 나뉘어 연구가 활발히 진행되고 있다. 하나는 PointNet처럼 Point Cloud 데이터를 있는 그대로 해석하는 인공지능 모델을 연구하는 ‘Point based method’이고, 다른 하나는 VoxelNet, SECOND, PointPillars처럼 Point Cloud 데이터로부터 격자 단위의 Feature Map을 생성해 이를 해석하는 인공지능 모델을 연구하는 ‘Grid based method’이다. 두 방식 모두 최근에는 2D 이미지 데이터 인공지능 못지않게 활발히 연구가 진행되고 있고, 자율주행, 로봇 주행, HD 맵 제작 등 일부 산업에서도 적용되어 연구되고 있다.
정리
2차원의 이미지 데이터를 다루는 인공지능 모델들이 급격한 속도로 발전한 것에 비하면 3차원 Point Cloud 데이터를 다루는 인공지능 모델의 발전 속도는 그리 빠르지 못했다. 필자는 그 원인을 Point Cloud 데이터가 가진 성질로 인해 진입장벽이 매우 높았던 것으로 보고 있다. 하지만 이러한 문제들은 극복이 되었고, 3D 인공지능의 발전 속도는 이전보다 훨씬 빠르다. 앞으로의 인공지능 데이터셋은 3차원으로 확장되어 매우 빠르게 진행될 것으로 전망한다.
현재 테스트웍스는 Point Cloud 데이터와 이를 다루는 여러 3D 인공지능 모델을 분석하고 있다. 다음 연재를 통해 테스트웍스의 Point Could 데이터에 최적화된 수집 가공 자동화 방법에 대해 소개하려고 한다. 이를 통해, 3D 인공지능 기술을 명확히 파악하고 Point Cloud 데이터셋의 구축을 도와 2D를 넘어 3D를 활용한 인공지능이 개발되기를 기대한다.
참고문헌
[3] Yan Yan, et al. “SECOND: Sparsely Embedded Convolutional Detection”. (2018)
[4] Alex H. Lang, et al. “PointPillars: Fast Encoders for Object Detection from Point Clouds”. (2019)

박예성
연구원, AI 연구 개발팀
홍익대학교 기계시스템디자인공학 학사
한양대학교대학원 지능형로봇학과 공학 석사
한양대학교 지능로봇연구소에서 인공지능 기술을 활용한 로봇 연구를 수행하였다. 이후 컴퓨터 비전 및 딥러닝에 대해 관심을 갖고 현재 테스트웍스 AI 연구 개발팀에서 근무 중이다. GAN, 3D AI 부분을 연구하고 있다.