
이전 포스트에서는 LLM이 가지고 있는 약점 두 가지, 환각과 최신성에 대해 이야기했었습니다. 이번에는 이 두 문제를 해결하기 위해 제안된 RAG라는 기술에 대해 알아보려고 합니다. 연구 내용을 소개해 드리기 전에 하나 짚고 넘어가야 하는 것이 있습니다. 바로 발생 원인입니다. 원인을 알아야 문제를 고칠 수 있기 때문입니다. 하지만 안타깝게도 그 원인은 명확하게 밝혀지지 않았습니다.
LLM은 왜 환각을 일으킬까
언어 모델이 처음 사전 학습을 할 때 말뭉치(코퍼스)를 이용해 언어의 규칙 등 전반적인 언어에 대한 지식을 습득한다고 말씀드렸습니다. 더 정확히 말하자면, 트랜스포머 기반 모델들은 일부 단어가 빠진 채로 문장을 입력 받고, 이 빈 칸에 들어갈 단어를 추측하는 훈련 과정을 통해 학습합니다. 구체적으로 무엇을 보고 어떻게 계산해내는 것인지는 아무도 모르지만, 빈 칸을 채워내는 작업도, 이를 바탕으로 다른 분류 작업을 시켜 보아도 성능이 이전 모델에 비해 아주 좋았기 때문에 위의 훈련 과정을 통해 전반적인 언어에 대한 이해도가 생겼다고 추측합니다. 이 추측은 많은 연구자들에게 사실상 정설로 여겨지고 있습니다.
트랜스포머 구조를 기반으로 규모를 키워 만들어진 LLM들도 기본 학습 방법은 이전과 크게 다르지 않습니다. 답을 자연어로 생성할 때도 결국 훈련 받은 과정 그대로, 바로 다음 빈칸에 올 단어를 추측하여 출력합니다. 모델이 정확한 설명을 했다면 그건 모델이 대답을 생성해내면서 가장 그럴듯한 단어들을 계속해서 골라낸 결과가 우연치 않게 정답이었던 것 뿐이지, 모델이 그것이 사실임을 알고 일부러 그렇게 생성해낸 것은 아니라는 겁니다. 그렇기 때문에 모델은 언제든지 논리적으로 틀리거나 혹은 사실과 다른 문장을 생성해낼 수 있습니다. 단, 지금까지 봐온 수많은 문장들이 있기 때문에 매우 능청스럽고 자연스럽게 생성해냅니다. 이것이 바로 환각 현상입니다.
정보의 최신성 문제도 비슷한 맥락으로 추측되고 있습니다. 모델이 답변을 하는 것은 무언가 논리적인 추론을 하는 것이 아니라, 언어적으로 가장 그럴듯해 보이는 단어들을 계속해서 나열해내는 것이므로 들어본 적 없는 새로운 지식에 대해서는 제대로 답을 할 수 없는 것입니다. 즉, 양쪽 문제 다 모델이 지식을 내재하고 있는 것이 아니라는 점에서 기인한 현상이라고 볼 수 있습니다.
이 두 문제는 지난 포스트에서 설명 드렸던 것처럼 단순히 웃고 넘어가기에는 매우 심각한 문제이기 때문에, 많은 연구자들이 이 문제를 해결하기 위해 다양한 노력을 했습니다. 오늘은 이런 연구들 중에서 가장 각광 받고 있는 연구를 하나 소개해 드리려고 합니다. 2020년 등장한 RAG(Retrieval Augmented Generation)라고 불리는 기술이 바로 그것입니다.
두 마리 토끼를 한번에: RAG
단어 뜻을 그대로 해석하자면 정보를 추가로 가져와서(Retrieval), 합치고(Augmented), 이를 바탕으로 생성한다(Generation)는 것입니다. 모델에 내재된 지식이 없다면, 외부 지식을 참고할 수 있도록 하는 시스템을 붙여줘서 해결하고자 한 것입니다.
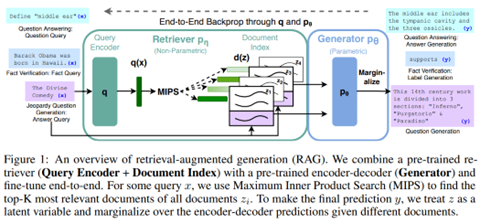
먼저 사용자로부터 질문을 입력 받으면 이를 인코딩하여 검색 시스템으로 보냅니다. 검색 시스템은 인코딩된 질문을 바탕으로 유사성이 높은 문서들을 검색해내고, 원본 질문과 이 문서들을 종합한 것을 바탕으로 답변을 생성해냅니다. 우리가 글을 쓸 때 팩트 체크를 위해 인터넷을 검색하는 것과 유사한 과정을 거치는 것입니다.
역사적으로 존재할 수 없는 두 객체에 대한 질문이 들어왔다면, 검색 시스템은 각각에 대한 정보를 데이터베이스에서 검색하게 됩니다. 더 풍부한 자료들을 바탕으로 서로 시대가 맞지 않다는 것을 확실하게 알게 되면, 없던 역사적 사건을 마음대로 지어내는 환각 증상을 예방할 수 있습니다. 용어 질문에 대해 전혀 다른 대답을 하는 경우도, 올바른 문서를 검색하여 해당 문서를 바탕으로 답변을 생성한다면 문제를 예방하는 것이 가능합니다.
데이터베이스가 모델의 학습 단계에 사용되는 것이 아니라, 모델이 답변을 생성하는 단계에서 사용되기 때문에 데이터베이스를 언제든지 조절해줄 수 있다는 장점이 있습니다. 이 말은, 데이터베이스를 언제나 최신 상태로 유지해 줄 수 있다는 뜻이기도 합니다. 즉, 정보의 최신성 관련 문제도 이것으로 해결할 수 있게 됩니다. 특정 분야에 특화된 챗봇을 만들려고 한다면, 데이터베이스에 관련 문서들을 보충해주는 것으로도 그 효과를 충분히 볼 수 있을 것으로 기대됩니다.
이번에는 환각 문제와 정보의 최신성 문제, 두 가지를 모두 완화 시킬 수 있는 RAG 기술에 대해 알아보았습니다. 물론 이것만 가지고 문제가 모두 완벽하게 해결되는 것은 아니지만, 모델 답변의 신뢰도를 높여줄 수 있다는 측면에서 많은 기대를 받고 있습니다. 더 연구가 활발하게 진행된다면 언젠 가는 100% 신뢰할 수 있는 답변을 내놓는 자연어 생성 시스템이 나타날 수 있지 않을까 하는 희망을 품으며, 이번 글을 마칩니다.

한승규
연구원, AI 연구 개발팀
고려대학교, 컴퓨터학과 석사
고려대학교 자연어처리 및 인공지능 연구실에서 자연어처리 관련 연구를 하였으며, 다양한 데이터 셋으로 모델을 파인튜닝하는 프로젝트들을 진행했다. 현재는 테스트웍스 AI 본부에서 LLM과 Multi-modal 관련 연구를 진행하고 있다.